欢迎阅读 The Huge Security Book!
《The Huge Security Book》(以下简称 HSB)是由 ChenMiao 发起并维护的一个开源技术书籍与知识分享项目。HSB 的核心目标是为所有计算机(系统)安全领域的初学者、爱好者以及希望深入理解信息安全技术的开发者,提供一份系统、易懂且实用的安全知识入门指南与学习资源集合。 本项目不仅致力于帮助读者快速掌握安全领域的基本概念,还鼓励他们以此为基础,进一步深入探索安全技术的奥秘,甚至投身于相关的研究与开发工作。与此同时,HSB 也承载着我个人在安全领域学习与实践过程中的思考与总结,因此它也可以被视作我的个人技术博客。
目前,HSB 项目正在针对于 Fuzzing 技术做出介绍,如果有任何不足之处,请及时点击此处进行上报!
项目结构
项目愿景
HSB 希望成为一座桥梁,连接对计算机安全感兴趣的初学者与复杂深奥的安全技术世界。我相信,每一位对安全充满好奇的人都值得拥有一个友好、系统且不断更新的学习平台。 通过这个项目,我希望:
- 降低入门门槛:以浅显易懂的语言和丰富的实例,帮助新手理解复杂的安全概念。
- 激发学习兴趣:通过介绍安全领域的趣味知识和实际案例,点燃读者的学习热情。
- 促进深入研究:为有志于深入安全领域的读者提供进阶资源和研究方向。
- 构建社区交流:鼓励读者参与讨论、贡献内容,共同建设一个互助互学的社区。
当前聚焦
目前,HSB 项目正在深入介绍 Fuzzing(模糊测试)技术,这是一种广泛应用于软件安全测试中的重要技术,用于发现程序中的潜在漏洞和缺陷。Fuzzing 通过向目标系统输入大量随机或半随机数据,监测其反应,从而找出可能导致崩溃或异常行为的输入,进而揭示潜在的安全隐患。
为什么选择 Fuzzing?
- 高效发现漏洞:Fuzzing 能够自动化地发现许多传统测试方法难以捕捉的漏洞。
- 广泛应用:从操作系统、网络协议到应用程序,Fuzzing 在各个层面都有广泛应用。
- 持续进化:随着技术的发展,Fuzzing 方法和工具也在不断进步,保持学习的新鲜感。
我在做什么?
- 基础知识介绍:解释 Fuzzing 的基本原理、类型(如模糊测试、覆盖率引导的模糊测试等)及其工作流程。
- 工具与框架:介绍常用的 Fuzzing 工具(如 AFL、LibFuzzer 等)及其使用方法。
- 实战案例:通过实际案例展示如何应用 Fuzzing 技术发现和修复漏洞。
- 进阶探讨:深入探讨 Fuzzing 的优化策略、研究前沿以及在实际项目中的应用挑战。
如何贡献本项目
欢迎各位读者对本项目 (The Huge Security Book)的阅读,如果在阅读期间有任何问题,可以点击此处进行上报,我会及时修复问题!
当然,本项目也欢迎各位读者的无私贡献,无论是投稿或者是支持更好的翻译或者是新增其他模块。在贡献之前,我们需要了解如何贡献本项目。
笔者的环境本地环境如下:
OS: Fedora 42(Server Edition)
Rust: cargo 1.91.0 (ea2d97820 2025-10-10)
mdbook: mdbook v0.4.52
The Huge Security Book 使用了 mdbook 进行构建,本节主要介绍了如何在用户本地自行搭建 The Huge Security Book 进行贡献,并介绍贡献的一些规范。
本项目目前支持的发行版本有:
- Fedora 42
- Ubuntu 24.04
至于其他发行版本,目前暂未支持,如读者在构建时发现其他发行版本可用,可提交 Pull Request 对本节的支持列表做出修改。
安装 Rust
- 国内用户
如果国内用户打算构建本项目,并且当前主机上没有rust,那么请参考rsproxy进行安装。
安装成功后,请检查对应版本,本项目要求\( rust \ version \ge 1.46 \)
cargo --version
cargo 1.91.0 (ea2d97820 2025-10-10)
- 国外用户
国外用户请直接参考rust进行安装:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
安装 mdbook
安装mdbook cli的方式有多种,本文档主要采用下方介绍的第一种方式,如有其他需要,请参考其他方式。
- 从crate.io中直接安装
cargo install mdbook
- 从github release上下载解压
wget https://github.com/rust-lang/mdBook/releases/download/v0.4.52/mdbook-v0.4.52-x86_64-unknown-linux-gnu.tar.gz
tar zxvf mdbook-v0.4.52-x86_64-unknown-linux-gnu.tar.gz
- 从crate.io中安装最新版本
cargo install --git https://github.com/rust-lang/mdBook.git mdbook
安装完成后,可以通过运行如下命令进行检查:
mdbook --version
mdbook v0.4.52
构建项目
完成上面的依赖安装后 (rust和mdbook),读者可以fork本仓库后,进行克隆到本地 (此处直接使用了上游仓库,请读者自行更换为对应的仓库链接):
git clone git@github.com:ChenMiaoi/huge-security-books.git
cd huge-security-books
然后可以直接开始构建,或查看构建命令:
make help
Available targets:
build - Build the mdBook
run - Build and serve the book on 0.0.0.0
watch - Watch & rebuild the book on changes
check-ci - Run tests and custom CI checks
clean - Clean build & cargo artifacts
Use 'make <target>' to run a specific action.
使用build命令进行构建:
2025-11-14 03:30:55 [INFO] (mdbook::book): Book building has started
2025-11-14 03:30:55 [INFO] (mdbook::book): Running the html backend
虚拟机配置
如果用户在物理机上构建,那么不需要参考这一小节。 如果使用虚拟机,在有防火墙的情况下无法直接查看到 The Huge Security Book 在浏览器的页面 (默认虚拟机是 server version with no GUI);因此需要关闭虚拟机防火墙,并将运行的监听 ip 绑定为“0.0.0.0“
# For Fedora
sudo systemctl stop firewalld
sudo systemctl disable firewalld
# For Ubuntu
sudo systemctl stop ufw
sudo systemctl disable ufw
使用run命令启动服务:
make run
2025-11-14 03:35:35 [INFO] (mdbook::book): Book building has started
2025-11-14 03:35:35 [INFO] (mdbook::book): Running the html backend
2025-11-14 03:35:35 [INFO] (mdbook::book): Book building has started
2025-11-14 03:35:35 [INFO] (mdbook::book): Running the html backend
2025-11-14 03:35:35 [INFO] (mdbook::cmd::serve): Serving on: http://0.0.0.0:3000
提交代码规范
假设已经做完任何更改,请使用check-ci命令进行检查,以便提交 Pull Request 时能够通过 CI 检查。
对于提交信息,本项目统一采用
commit_type(where): msg这样的格式进行修改:feat(src/contribution): Add how to contribute page for book顺带一提,请加上您的
Signed-off-by:git commit -s
make check-ci
number of HTML files scanned: 8
number of HTML redirects found: 0
number of links checked: 130
number of links ignored due to external: 10
number of links ignored due to exceptions: 0
number of intra doc links ignored: 0
errors found: 0
Link check completed successfully!
✅ Link checking completed successfully
🎉 All steps executed successfully. 🚀
Fuzzing
本章节主要介绍了 Fuzzing 技术,包括如下几个章节:
Introduce
The Fuzzing Book
The Fuzzing Book是 Andreas Zeller, Rahul Gopinath, Marcel Böhme, Gordon Fraser, Christian Holler 协力创作的一本专注于讲解 fuzzing test 技术的书籍。其中详细介绍了各种原理以及通过实际代码的例子进行讲解。这是一本不可多得的好书,但是由于该书只有网页版,并且是纯英文,如果想要本地进行阅览还必须通过 Jupyter 自行搭建环境构建。因此,本专栏主要针对于 the fuzzing book 的主要章节进行翻译,如有任何问题,请点击这里前往提出对应的问题。
作者声称这本书使用了近 20 万行代码以及超过 15 万行文本。
关于本书
软件存在缺陷,而发现缺陷可能需要大量精力。本书通过自动化软件测试来解决这个问题,特别是自动生成测试用例。近年来涌现的新技术使测试生成和软件测试取得了显著进步。这些技术现已成熟到足以集结成书——甚至包含可执行代码。
谁适合阅读这本书?
本书可作为软件测试或安全测试课程的教材,也可作为软件测试、安全测试或软件工程课程的补充资料,同时适合软件开发人员参考学习。内容涵盖随机模糊测试、基于变异的模糊测试、基于语法的测试生成、符号化测试等多种技术,并通过可实操的代码示例演示所有方法。
Sitemap
虽然本书各章节可按顺序阅读,但读者也可根据兴趣选择不同学习路径。图中箭头 \( A \rightarrow B \) 表示章节 A 是章节 B 的先修内容。您可以在图中任意选择路径,直达最感兴趣的主题:
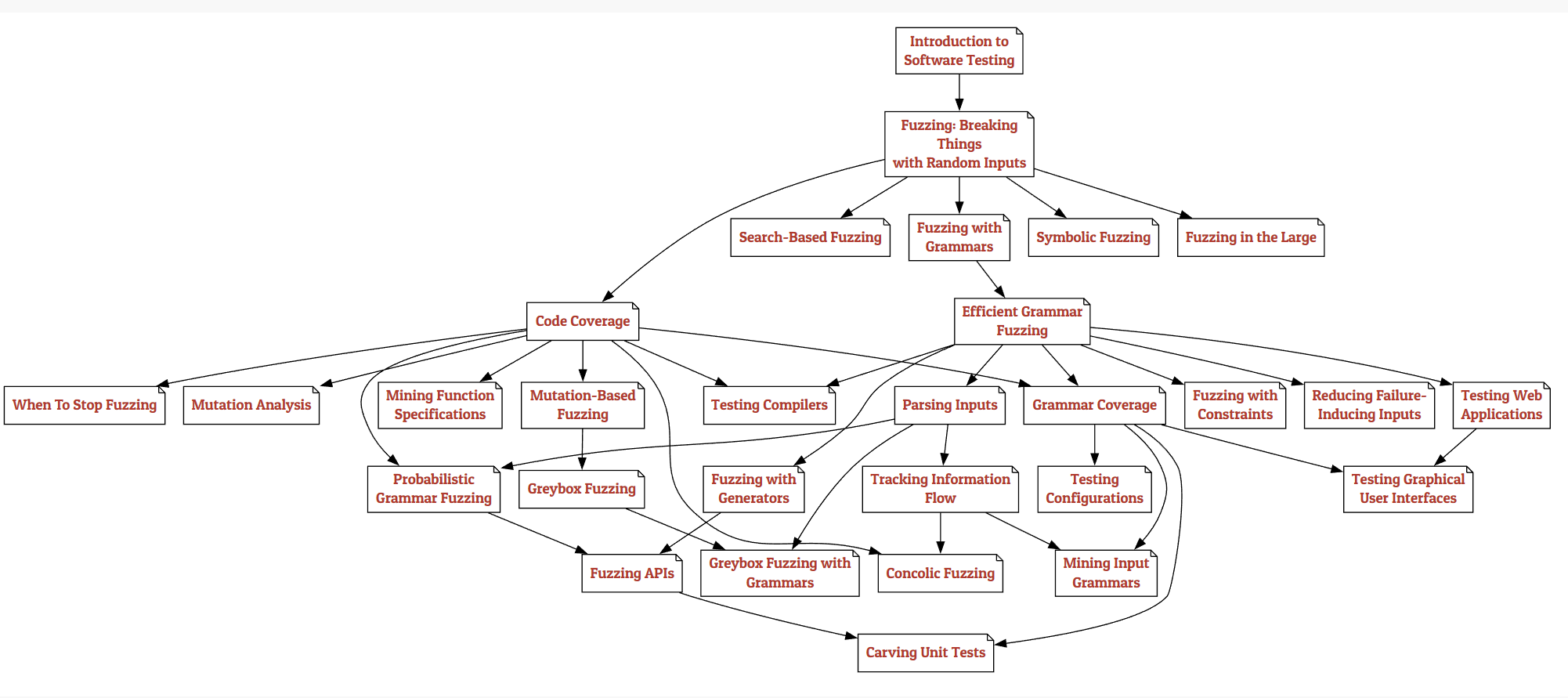
- 目录
- Part Ⅰ: Whetting Your Appetite: 这个章节会介绍这本书各个话题的概要
- Tours through the Book: 本书体量庞大,包含超过 2 万行代码和 15 万文字内容,若印刷成册将超过 1200 页。显然,我们并不要求读者通读全书。
- Introduction to Software Testing: 在进入本书核心内容前,我们先介绍软件测试的基本概念。为何必须进行软件测试?如何实施软件测试?如何判定测试是否成功?怎样确认测试是否充分?本章将回顾关键概念,同时引导读者熟悉 Python 和交互式 notebook 的使用。
- Part Ⅱ: Lexical Fuzzing: 本部分介绍词法层面的测试生成,即构建字符序列的方法。
- Fuzzing: Breaking Things with Random Inputs: 本章将介绍最简单的测试生成技术之一。随机文本生成(又称模糊测试)的核心思想是向程序输入随机字符序列,以期发现程序缺陷。
- Code Coverage: 上一章我们介绍了基础模糊测试——即生成随机输入来测试程序。如何衡量这些测试的有效性?一种方法是统计发现缺陷的数量(及严重程度);但当缺陷稀少时,我们需要一个能反映测试发现缺陷概率的替代指标。本章将引入代码覆盖率的概念,用于衡量测试运行期间程序实际被执行的部分。对于试图覆盖尽可能多代码的测试生成器而言,覆盖率测量也至关重要。
- Mutation-Based Fuzzing: 大多数随机生成的输入在语法上是无效的,因此会很快被处理程序拒绝。为了测试输入处理之外的功能,我们必须提高获得有效输入的概率。其中一种方法是通过变异模糊测试——即对现有输入进行微小改动,这些改动可能保持输入有效性,同时激发新的程序行为。我们将演示如何创建这类变异,并如何引导它们覆盖未被测试的代码,应用流行模糊测试工具 AFL 的核心概念。
- Greybox Fuzzing: 前一章介绍了基于变异的模糊测试技术,该方法通过对给定输入进行微小变异来生成测试用例。本章将展示如何引导这些变异实现特定目标(如提高代码覆盖率)。相关算法源自著名的American Fuzzy Lop(AFL)模糊测试工具,特别是其AFLFast和AFLGo变种。我们将探讨 AFL 背后的灰盒模糊测试算法,以及如何利用它解决自动化漏洞检测中的各类问题。
- Search-Based Fuzzing: 有时我们不仅关注生成尽可能多样化的程序输入,更希望获得能实现特定目标(如触发程序中特定语句)的测试输入。当我们明确寻找目标时,就可以通过搜索算法实现。搜索算法是计算机科学的核心,但将广度优先或深度优先等经典搜索算法直接应用于测试用例搜索并不现实,因为这些算法可能需要遍历所有可能的输入。不过,领域知识能帮助我们突破这一局限。例如,若能评估多个程序输入中哪个更接近目标,这种信息就能引导我们快速抵达目标——这种引导信息被称为启发式规则。系统化应用启发式规则的方法被归纳为元启发式搜索算法。“元“意味着这些算法具有通用性,可针对不同问题实例化。元启发式算法常借鉴自然界的运行机制,例如模拟进化过程、群体智能或化学反应的算法。总体而言,它们比穷举搜索高效得多,能应对极其庞大的搜索空间——即便是程序输入域这样巨大的搜索空间对它们也不成问题。
- Mutation Analysis: 在关于代码覆盖率的章节中,我们演示了如何识别程序被执行的部分,从而评估测试用例集覆盖程序结构的有效性。然而,仅凭覆盖率可能并非衡量测试有效性的最佳标准,因为即使覆盖率很高,也可能从未验证结果的正确性。本章将介绍另一种评估测试套件有效性的方法:通过向代码中注入变异(即人为缺陷),检验测试套件能否检测到这些人为故障。其核心思想是,如果测试套件无法识别这类变异,那么它同样可能漏掉真实存在的缺陷。
- Part Ⅰ: Whetting Your Appetite: 这个章节会介绍这本书各个话题的概要
Part Ⅰ: Whetting Your Appetite
本部分将介绍全书的核心主题。
Tours through the Book
这本书使用了 2 万多行代码以及超过了 15 万行的文本文字书写,因此作者并不希望读者全部浏览一遍,而是有计划的进行阅读。在下方,给出了一些不同目的的人士可能想要阅读的章节顺序。
实用者路线
您有一个需要测试的程序。您希望尽可能快速且彻底地生成测试用例。您并不太关心功能是如何实现的,只要它能完成任务就行。您的目的是学会如何使用这些工具/功能。
- 首先从导论开始,掌握基本概念。(不过这些内容您多半已经了解了,但快速回顾一下总没坏处)。
- 使用模糊测试器一章中介绍的基础模糊测试器,用最初的随机输入来测试您的程序。
- 获取程序的覆盖率数据,并利用这些覆盖率信息来引导测试生成,以提高代码覆盖率。
- 为您的程序定义一个输入语法,并使用该语法,通过生成语法正确的输入来彻底地对程序进行模糊测试。我们推荐使用语法覆盖模糊测试器,因为它能确保对输入元素的覆盖。
- 如果您希望对生成的输入有更多控制,可以考虑使用概率性模糊测试或基于生成器函数的模糊测试。
- 如果您需要部署大规模的模糊测试集群,请学习如何管理大量模糊测试器。
Introduction to Software Testing
在进入本书的核心内容之前,让我们先介绍软件测试的基本概念。为什么要测试软件?如何测试软件?如何判断一个测试是否成功?如何知道是否已经测试足够?在本章中,让我们回顾最重要的概念,同时熟悉 Python 和交互式笔记本。
本章(以及本书)并非旨在取代一本测试教科书;请参阅文末的背景部分,了解推荐的阅读材料。
Simple Testing
让我们从一个简单的例子开始。您的同事被要求实现一个平方根函数 \( \sqrt{x} \) 。(我们暂且假设当前环境中还没有这个函数。)在研究完Newton-Raphson方法后,她提出了下面的 Python 代码,并声称这个 my_sqrt() 函数确实可以计算平方根。
#![allow(unused)]
fn main() {
fn my_sqrt(x: f64) -> f64 {
/// Computes the square root of x, using the Newton-Raphson method
let mut approx = x / 2.0;
let mut guess = (approx + x / approx) / 2.0;
while approx != guess {
approx = guess;
guess = (approx + x / approx) / 2.0;
}
approx
}
}您现在的任务是去验证这个函数是否真的能做到它声称的功能。
Understanding Python Programs
此处不再对 Python 的概念进行介绍。
在本项目中,部分简单代码会通过 Rust 进行重写,这样就能够使得读者在阅读时直接在网页中运行代码,而不需要自行搭建环境。例如:
#![allow(unused)]
fn main() {
fn my_sqrt(x: f64) -> f64 {
let mut approx = x / 2.0;
let mut guess = (approx + x / approx) / 2.0;
while approx != guess {
approx = guess;
guess = (approx + x / approx) / 2.0;
}
approx
}
println!("{}", my_sqrt(4.0));
}Automating Test Execution
到目前为止,我们一直采用手动方式测试上述程序,即手动运行并人工检查结果。这是一种非常灵活的测试方法,但从长远来看,效率相当低下:
- 手动检查的执行次数及其结果非常有限
- 程序有任何更改后,都必须重复测试过程
这就是为什么自动化测试非常有用。一种简单的方法是让计算机先进行计算,然后再检查结果。
例如,这段代码会自动测试 \( \sqrt{4} = 2 \) 是否成立:
#![allow(unused)]
fn main() {
fn my_sqrt(x: f64) -> f64 {
let mut approx = x / 2.0;
let mut guess = (approx + x / approx) / 2.0;
while approx != guess {
approx = guess;
guess = (approx + x / approx) / 2.0;
}
approx
}
let result = my_sqrt(4.0);
let expected_result = 2.0;
if result == expected_result {
println!("Test passed")
} else {
println!("Test failed")
}
}这个测试的好处在于我们可以反复运行它,从而确保至少能正确计算出 4 的平方根。不过,仍然存在一些问题:
- 我们需要五行代码来编写一个测试
- 我们不在乎四舍五入误差
- 我们只检查一个输入(以及一个结果)
让我们逐一解决这些问题。首先,让我们让测试更紧凑一些。几乎所有编程语言都有一种自动检查条件是否成立并在不成立时停止执行的方法。这被称为断言,对于测试非常有用。
在 Python 中, assert 语句接受一个条件,如果条件为真,则什么都不会发生。(如果一切按预期工作,你就不应该感到困扰。)然而,如果条件评估为假, assert 会引发一个异常,表示一个测试刚刚失败。
#![allow(unused)]
fn main() {
fn my_sqrt(x: f64) -> f64 {
let mut approx = x / 2.0;
let mut guess = (approx + x / approx) / 2.0;
while approx != guess {
approx = guess;
guess = (approx + x / approx) / 2.0;
}
approx
}
assert!(my_sqrt(4.0) == 2.0);
}The Limits of Testing
在原书中做了多种测试对上面的 my_sqrt 函数进行了验证。请记住,尽管我们竭尽全力进行测试,但您始终只是在针对一组有限的输入来检验功能。因此,总可能存在未经测试的输入,导致函数在这些情况下仍可能出错。
例如,如果此时这个程序计算 \( \sqrt{0} \),就会导致除零错误。
my_sqrt(0)
在我们目前的测试中,并未验证这种情况(即 \( \sqrt{0} = 0 \) 的条件)。这意味着,一个基于 \( \sqrt{0} = 0 \) 这一前提的程序会意外地失败。但即使我们将随机生成器的输入范围设置为 0 到 1000000(而非 1 到 1000000),它恰好生成零值的概率仍是百万分之一。如果一个函数在少数特定值上的行为截然不同,简单的随机测试很难覆盖到这些情况。
因此,我们必须记住,尽管广泛的测试可以让我们对程序的正确性有高度的信心,但它并不能保证程序在所有的未来执行中都是正确的。即使是运行时验证(它会检查每一个结果),也只能保证如果它产生了一个结果,那么这个结果将是正确的;但并不能保证未来的执行不会导致检查失败。
这正是我们在本课程后续内容中要做的事情:设计能帮助我们彻底测试程序的技术,以及帮助我们检查其状态正确性的方法。祝您学习愉快!
Backgroud
- An all-new modern, comprehensive, and online textbook on testing is “Effective Software Testing: A Developer’s Guide” [Maurício Aniche, 2022]
- For this book, we are also happy to recommend “Software Testing and Analysis”[Pezzè et al, 2008]
- Other important must-reads with a comprehensive approach to software testing, including psychology and organization, include “The Art of Software Testing”[Myers et al, 2004] as well as “Software Testing Techniques” [Beizer et al, 1990].
Exercise
Testing Shellsort
考虑以下 shellsort 函数的实现,它接受一个元素列表并 (推测性地) 对其进行排序:
#![allow(unused)]
fn main() {
fn shellsort(elems: &[i32]) -> Vec<i32> {
let mut sorted_elems = elems.to_vec();
let gaps = [701, 301, 132, 57, 23, 10, 4, 1];
for gap in gaps {
for i in gap..sorted_elems.len() {
let temp = sorted_elems[i];
let mut j = i;
while j >= gap && sorted_elems[j - gap] > temp {
sorted_elems[j] = sorted_elems[j - gap];
j -= gap;
}
sorted_elems[j] = temp;
}
}
sorted_elems
}
}你的任务是使用各种输入彻底测试 shellsort():
- 手动测试用例
- 随机输入
Part Ⅱ: Lexical Fuzzing
Fuzzing: Breaking Things with Random Inputs
在本章中,我们将从最简单的测试生成技术之一开始。随机文本生成(也称为模糊测试)的核心思想是向程序输入一串随机字符,以期发现程序中的故障。
- 前提条件:
- 你应该了解过软件测试的基础只是;例如,从软件测试导论这一章中。
- 你应该对
Python有相当的了解。
A Testing Assignment
模糊测试诞生于“dark and stormy night in the Fall of 1988” [Takanen 等人,2008]。当时,Barton Miller 教授正坐在他位于威斯康星州麦迪逊市的公寓里,通过一条 1200 波特的电话线连接到他的大学计算机。雷暴在线上引起了噪音,而这些噪音又导致两端的 UNIX 命令接收到错误输入——并导致崩溃。频繁的崩溃让他感到惊讶——程序本应比这更加健壮才对啊?作为科学家,他想深入研究这个问题的严重程度及其成因。于是,他为威斯康星大学麦迪逊分校的学生设计了一个编程练习——这个练习将让他的学生们创造出第一批模糊测试器。
以下是作业的内容
该项目的目标是评估各种 UNIX 实用程序在接收到不可预测的输入流时的鲁棒性。[…] 首先,你需要构建一个模糊生成器。这是一个会输出随机字符流的程序。其次,你将使用这个模糊生成器来攻击尽可能多的 UNIX 实用程序,目标是试图使它们崩溃。
这项任务抓住了模糊测试的精髓:生成随机输入,然后观察它们是否会引发程序故障。只要让它运行足够长的时间,你就会看到结果。
A Simple Fuzzer
让我们尝试完成这个任务,构建一个模糊生成器。其核心思路是生成随机字符,将它们添加到一个缓冲区字符串变量 (out) 中,最后返回这个字符串。
def fuzzer(
max_length: int = 100,
char_start: int = 32,
char_range: int = 32
) -> str:
string_length = random.randrange(0, max_length + 1)
out = ""
for i in range(0, string_length):
out += chr(random.randrange(char_start, char_start + char_range))
return out
如上面代码所示,这就是一个简单实际的 fuzzer 函数。使用默认参数时, fuzzer() 函数返回一串随机字符:
'!7#%"*#0=)$;%6*;>638:*>80"=</>(/*:-(2<4 !:5*6856&?""11<7+%<%7,4.8,*+&,,$,."'
Bart Miller 将这种随机的、无结构的数据命名为 fuzz。现在试想,如果这个 fuzz 字符串被输入到一个需要特定输入格式(例如逗号分隔的值列表或电子邮件地址)的程序中,该程序能否毫无问题地处理这样的输入?
如果上述模糊测试输入已经让你觉得有趣,那么请设想一下:我们可以轻松设置模糊测试器来生成其他类型的输入。例如,我们也可以让 fuzzer() 生成一系列小写字母。这里我们使用 ord(c) 来返回字符 c 的 ASCII 码。
fuzzer(1000, ord('a'), 26)
Fuzzing External Programs
让我们看看如果实际用模糊测试生成的输入来调用外部程序会发生什么。为此,我们将分两步进行:首先创建一个包含模糊测试数据的输入文件,然后将这个输入文件提供给目标程序。
Creating Input Files
basename = "input.txt"
tempdir = tempfile.mkdtemp()
FILE = os.path.join(tempdir, basename)
print(FILE)
这样我们就创建了一个临时文件。现在我们可以打开这个文件进行写入。Python 的 open() 函数会打开一个文件,之后我们就可以向其中写入任意内容。它通常与 with 语句结合使用,这样可以确保文件在使用完毕后会被立即关闭。
data = fuzzer()
with open(FILE, "w") as f:
f.write(data)
contents = open(FILE).read()
print(contents)
assert(contents == data)
Invoking External Programs
现在我们有了输入文件,就可以在其上调用程序了。为了增加趣味性,我们来测试一下 bc 计算器程序,这个程序会接收一个算术表达式并对其进行求值。
program = "bc"
with open(FILE, "w") as f:
f.write("2 + 2\n")
result = subprocess.run(
[program, FILE],
stdin=subprocess.DEVNULL,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True
)
result.stdout
我们可以通过运行结果来检查程序的输出。对于 bc 程序来说,result.stdout 就是算术表达式的求值结果。我们还可以检查其退出状态码:值为 0 表示程序正常终止。任何错误信息都会显示在 results.stderr 中。实际上,您可以用任何您喜欢的程序来替代 bc。但请注意,如果您的程序有能力更改甚至损坏您的系统,那么存在相当大的风险——模糊测试生成的输入数据或命令很可能恰好会触发这种破坏性操作。
仅仅出于有趣的设想,假设您要测试一个文件删除程序——比如
rm -fr FILE,其中 FILE 是由fuzzer()生成的字符串。那么,fuzzer()(使用默认参数)产生一个会导致删除您所有文件的 FILE 参数的可能性有多大呢?
实际上,这种可能性可能比您想象的要高。例如,如果您删除 /(即文件系统的根目录),那么您的整个文件系统都会消失。如果您删除 .(当前目录),那么当前目录中的所有文件都会消失。
生成一个恰好为 1 个字符长的字符串的概率是 \( \frac{1}{101} \)。这是因为字符串的长度是通过调用 random.randrange(0, max_length + 1) 来确定的,其中 max_length 的默认值为 100。根据对 random.randrange 的描述,它应该返回 \( [0, 99 + 1) \) 范围内的一个随机数。因此,我们最终得到的是包含两端点的区间 \( [0, 100] \),该区间内共有 101 个可能的值。
要生成 / 或 .,你需要满足两个条件:字符串长度必须为 1(概率:101 分之一),并且字符必须是这两个字符之一(概率:32 分之二)。
\[ \frac{1}{101} \times \frac{2}{32} = 0.0006188118811881188 \]
上述代码块排除了删除 ~(您的主目录)的可能性,这是因为生成字符 ~ 的概率不是 1/32,而是 0/32。字符是通过调用 chr(random.randrange(char_start, char_start + char_range)) 创建的,其中 char_start 的默认值为 32,char_range 的默认值为 32。chr 函数的文档说明:“返回表示 Unicode 码点为整数 i 的字符的字符串”。字符 ~ 的 Unicode 码点是 126,因此不在区间 \( [32, 64) \) 内。
如果代码被修改,使 char_range = 95,那么获得字符 ~ 的概率将是 1/94,从而导致(删除所有文件的)事件概率等于 0.000332。这样一来,您主目录中的所有文件都将消失。
\[ \frac{3}{94} \times \frac{1}{94} \times \frac{99}{101} = 0.0003327969736765437 \]
然而,实际上只要字符串的第二个字符是空格,任何内容都可能造成破坏——毕竟,rm -fr / WHATEVER 会先处理 /,然后再处理后面的内容。第一个字符是 / 或 . 的概率是 2/32,因为上面的代码块只允许生成 / 或 .,而不包含 ~。
对于空格字符,其出现概率是 \( \frac{1}{32} \)。我们必须引入“字符串长度至少为 2 个字符“这一事件的概率项,因为只有满足这个条件,才可能出现第二个字符是空格的情况。这个概率是 \( \frac{99}{101} \),因为它等于 1 减去(字符串长度为 0 或 1 个字符的概率),即 \( 1 - \frac{2}{101} \)。
因此,在第二个字符是空格的情况下,导致删除所有文件的事件概率计算为:
\[ P_{del} = P_{‘/’\ or\ ‘.’} \times P_{’\ ’} \times P_{2 char} = \frac{2}{32} \times \frac{1}{32} \times \frac{99}{101} = 0.0019144492574257425 \]
考虑到模糊测试通常要运行数百万次,您绝对不想冒这个风险。请在一个可以随意重置的安全环境(例如 Docker 容器)中运行您的模糊测试器。
Long-Running Fuzzing
现在让我们将大量输入数据馈送到被测程序中,以观察它是否会在某些输入上崩溃。我们将所有结果(输入数据与实际运行结果成对)存储在 runs 变量中。(注意:运行此操作可能需要一些时间。)
trials = 100
program = "bc"
runs = []
for i in range(trials):
data = fuzzer()
with open(FILE, "w") as f:
f.write(data)
result = subprocess.run([program, FILE],
stdin=subprocess.DEVNULL,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True)
runs.append((data, result))
我们现在可以查询 runs 变量以获取一些统计信息。例如,我们可以查询有多少次运行实际通过了——也就是说,没有产生错误信息。
sum(1 for (data, result) in runs if result.stderr == "")
大多数输入显然是无效的——这并不奇怪,因为随机输入不太可能包含有效的算术表达式。
Bugs Fuzzers Find
当 Miller 和他的学生在 1989 年运行他们的第一批模糊测试器时,他们发现了一个令人震惊的结果:大约有三分之一的被测试 UNIX 实用程序存在问题——它们在面对模糊测试输入时会崩溃、挂起或以其他方式失效 Miller 等人,1990。这其中也包括上面提到的 bc 程序。(不过上面使用的 bc 是一个现代重新实现的版本,其作者是模糊测试的坚定拥护者!)
考虑到当时许多这类 UNIX 实用程序被用于处理网络输入的脚本中,这个结果可谓敲响了警钟。程序员们迅速构建并运行自己的模糊测试器,紧急修复已报告的错误,并从此学会了不再轻信外部输入。
Miller 的模糊测试实验究竟发现了哪些问题?事实证明,1990 年程序员们犯的错误,与今天人们犯的错误如出一辙。
Buffer Overflows
许多程序对输入及输入元素的长度设有内置限制。在 C 这类语言中,很容易在程序(甚至程序员)毫无察觉的情况下超出这些长度限制,从而引发所谓的缓冲区溢出。例如,下面这段代码会直接将输入字符串复制到工作日字符串中,即使输入超过八个字符也不例外:
char weekday[9]; // 8 characters + trailing '\0' terminator
strcpy (weekday, input);
具有讽刺意味的是,当输入是 “Wednesday”(9 个字符)时,这个问题就会暴露:多出的字符(这里的 ‘y’ 和随后的字符串终止符 ‘\0’)会直接覆盖到 weekday 之后的内存区域,从而引发不可预知的行为——比如可能改变某个布尔字符变量的值,使其从 ‘n’ 变为 ‘y’。通过模糊测试,可以非常容易地生成超长输入和输入元素。
我们可以在 Python 函数中轻松模拟这种缓冲区溢出行为:
def crash_if_too_long(s):
buffer = "Thursday"
if len(s) > len(buffer):
raise ValueError
from ExpectError import ExpectError
trials = 100
with ExpectError():
for i in range(trials):
s = fuzzer()
crash_if_too_long(s)
上述代码中的 with ExpectError() 行确保打印错误消息,但程序会继续执行;这是为了将此“预期“错误与其他代码示例中的“非预期“错误区分开来。
Missing Error Checks
许多编程语言并不支持异常机制,而是在异常情况下让函数返回特殊的错误码。例如,C 语言中的 getchar() 函数通常从标准输入返回一个字符;如果没有更多输入可用,则返回特殊值 EOF(文件结束符)。现在假设程序员正在扫描输入以读取下一个字符,使用 getchar() 不断读入字符,直到读取到空格字符为止:
while (getchar() != ' ');
如果输入提前结束(这在模糊测试中是完全可以出现的情况)会发生什么?答案是:getchar() 会返回 EOF,并且再次被调用时会持续返回 EOF;因此上面的代码会直接陷入无限循环。
当然,我们可以模拟出这种缺失的错误检查,假如这是一个输入中没有空格就会挂起的函数:
def hang_if_no_space(s):
i = 0
while True:
if i < len(s):
if s[i] == ' ':
break
i += 1
trials = 100
with ExpectTimeout(2):
for i in range(trials):
s = fuzzer()
hang_if_no_space(s)
利用我们在测试导论中介绍的超时机制,我们可以在一定时间后中断这个函数。确实,在几次模糊输入后,它确实会陷入挂起状态。
Rogue Numbers
通过模糊测试,可以轻松在输入中生成不常见的值,从而引发各种有趣的行为。请看下面这段同样用 C 语言编写的代码,它首先从输入中读取一个缓冲区大小,然后分配一个指定大小的缓冲区:
char *read_input() {
size_t size = read_buffer_size();
char *buffer = (char *)malloc(size);
// fill buffer
return (buffer);
}
如果 size 值非常大,超过了程序内存限制会怎样?如果 size 小于后续字符数量会怎样?如果 size 是负数又会怎样?通过在此处提供随机数值,模糊测试可以引发各种类型的破坏。
同样地,我们可以在 Python 中轻松模拟这类异常数值。如果传入的字符串值在转换为整数后过大,函数 collapse_if_too_large() 就会执行失败。
def collapse_if_too_large(s):
if int(s) > 1000:
raise ValueError
long_number = fuzzer(100, ord('0'), 10)
print(long_number)
with ExpectError():
collapse_if_too_large(long_number)
如果我们真的试图在系统上分配如此大量的内存,像上面那样快速失败反而是更可取的方案。实际上,内存耗尽会急剧降低系统运行速度,甚至导致系统完全无响应——此时重启就成了唯一的选择。
有人可能会争辩说,这些都是糟糕的编程方式或糟糕的编程语言导致的问题。但现实是,每天都有成千上万的人开始学习编程,即使到了今天,他们仍在反复犯着同样的错误。
Cathcing Errors
当 Miller 和他的学生构建第一个模糊测试器时,他们能识别错误,仅仅是因为程序会崩溃或挂起——这两种状态很容易判断。然而,如果故障更加隐蔽,我们就需要设计额外的检查机制。
Generic Checkers
如上所述,缓冲区溢出是一个更普遍问题的具体表现:在 C 和 C++ 这类语言中,程序可以访问其内存的任意部分——甚至是未初始化的、已释放的或根本不属于你试图访问的数据结构的内存区域。如果你要编写操作系统,这种能力是必要的;如果你追求极致性能或控制力,这也很棒;但如果你想避免错误,这就相当糟糕了。幸运的是,有一些工具可以在运行时帮助捕获此类问题,当它们与模糊测试结合使用时效果极佳。
Checking Memory Accesses
为了在测试期间捕获有问题的内存访问,可以在特殊的内存检查环境中运行 C 程序;这些工具会在运行时检查每一个内存操作,确认其访问的内存是否有效且已初始化。LLVM Address Sanitizer 就是一个流行范例,它能检测一整类潜在的危险性内存安全违规行为。在接下来的示例中,我们将使用该工具编译一个相当简单的 C 程序,并通过读取已分配内存区域之外的内容来故意引发一次越界读取。
#include <stdlib.h>
#include <string.h>
int main(int argc, char** argv) {
/* Create an array with 100 bytes, initialized with 42 */
char *buf = malloc(100);
memset(buf, 42, 100);
/* Read the N-th element, with N being the first command-line argument */
int index = atoi(argv[1]);
char val = buf[index];
/* Clean up memory so we don't leak */
free(buf);
return val;
}
我们启用地址清理功能来编译这个 C 程序:
clang -fsanitize=address -g -o program program.c
如果我们通过传递参数 99 运行该程序,它会返回 buf[99] 的值,即 42。
./program 99; echo $?
program(2097,0x1ff330240) malloc: nano zone abandoned due to inability to reserve vm space.
42
然而,访问 buf[110]会导致 AddressSanitizer 报告越界错误。
./program 110
program(2132,0x1ff330240) malloc: nano zone abandoned due to inability to reserve vm space.
=================================================================
==2132==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x60b0000000ae at pc 0x000104927e84 bp 0x00016b4daa50 sp 0x00016b4daa48
READ of size 1 at 0x60b0000000ae thread T0
#0 0x104927e80 in main program.c:12
#1 0x1956d0270 (<unknown module>)
0x60b0000000ae is located 10 bytes after 100-byte region [0x60b000000040,0x60b0000000a4)
allocated by thread T0 here:
#0 0x104e58c04 in malloc+0x94 (libclang_rt.asan_osx_dynamic.dylib:arm64e+0x54c04)
#1 0x104927dc8 in main program.c:7
#2 0x1956d0270 (<unknown module>)
......
如果您想在 C 程序中查找错误,在模糊测试时启用这类检查相当容易。这会使执行速度降低一定倍数(具体取决于工具,对于 AddressSanitizer 通常是 2 倍),同时消耗更多内存,但与人工发现这些错误所需付出的精力相比,CPU 周期成本简直微不足道。
内存越界访问会带来严重的安全风险,因为它可能允许攻击者访问甚至修改本不该被其获取的信息。一个著名的例子是 Heartbleed 漏洞,它是 OpenSSL 库中的一个安全缺陷,该库负责实现为计算机网络提供通信安全性的加密协议。(如果您正在通过浏览器阅读本文,内容很可能正是使用这些协议加密的。)
Heartbleed 漏洞的利用方式是向 SSL 心跳服务发送特制的命令。心跳服务用于检查另一端的服务器是否仍处于活动状态。客户端会向该服务发送一个类似以下示例的字符串:
BIRD (4 letters)
服务器会回复 BIRD 作为响应,客户端由此可知服务器处于活动状态。
不幸的是,通过要求服务器返回比请求字母集更多的内容,该服务可能被利用。这一点在下面的 XKCD 漫画 中得到了生动的解释:

在 OpenSSL 的实现中,这些内存内容可能包含加密证书、私钥等敏感信息——更糟糕的是,没有人会察觉到这片内存刚被访问过。当 Heartbleed 漏洞被发现时,它已存在多年,无人知晓是否有秘密数据已经泄露、具体泄露了哪些数据;紧急设立的 Heartbleed 公告页面 说明了一切。
但 Heartbleed 漏洞是如何被发现的呢?非常简单。Codenomicon 公司和谷歌的研究人员使用内存清理器编译了 OpenSSL 库,然后愉快地用模糊测试生成的命令对其进行了密集测试。内存清理器会检测是否发生了越界内存访问——而实际上,它非常迅速地发现了这一问题。
内存检查器只是众多可在模糊测试期间检测运行时错误的检查器之一。在 mining function specifications 章节中,我们将进一步学习如何定义通用检查器。
Information Leaks
信息泄露不仅可能通过非法内存访问发生,也可能在“有效“内存范围内出现——如果这片“有效“内存包含本不应泄露的敏感信息。让我们通过一个 Python 程序来说明这个问题。首先,创建一些包含真实数据和随机数据的程序内存:
secrets = ("<space for reply>" + fuzzer(100) +
"<secret-certificate>" + fuzzer(100) +
"<secret-key>" + fuzzer(100) + "<other-secrets>")
我们向 secrets 中添加更多“内存“字符,并用 “deadbeef” 作为未初始化内存的标记进行填充:
uninitialized_memory_marker = "deadbeef"
while len(secrets) < 2048:
secrets += uninitialized_memory_marker
我们定义一个服务(类似于上文讨论的心跳服务),该服务接收待回复的内容和长度参数。它会将待回复内容存储在内存中,然后按给定长度发回。
def heartbeat(reply: str, length: int, memory: str) -> str:
# Store reply in memory
memory = reply + memory[len(reply):]
# Send back heartbeat
s = ""
for i in range(length):
s += memory[i]
return s
这对于标准字符串完全有效:
heartbeat("potato", 6, memory=secrets)
然而,如果长度参数大于回复字符串的实际长度,内存中的额外内容就会泄露出去。请注意,所有这些操作仍然发生在常规数组边界内,因此地址清理器不会被触发:
heartbeat("hat", 500, memory=secrets)
如何检测这类问题?思路是识别本不应泄露的信息,例如给定的密钥,也包括未初始化的内存。我们可以通过一个小的 Python 示例来模拟这种检查:
with ExpectError():
for i in range(10):
s = heartbeat(fuzzer(), random.randint(1, 500), memory=secrets)
assert not s.find(uninitialized_memory_marker)
assert not s.find("secret")
通过此类检查,我们发现密钥和/或未初始化内存确实发生了泄露。在information flow章节中,我们将讨论如何自动化实现这一点——通过“污点标记“敏感信息及其衍生值,并确保被“污染“的值不会泄露出去。
根据经验法则,在模糊测试期间应始终启用尽可能多的自动检查器。CPU 周期是廉价的,而错误的代价是高昂的。如果只是单纯运行程序而没有实际检测错误的机制,你会错失大量发现问题的机会。
Program-Specific Checkers
除了适用于特定平台或语言中所有程序的通用检查器之外,您还可以设计专用于您的程序或子系统的特定检查器。在测试章节中,我们已经提及了运行时验证技术,该技术会在运行时检查函数结果的正确性。
早期检测错误的一个核心思想是断言(assertion)概念——即检查重要函数的输入(前置条件)和结果(后置条件)的谓词。程序中嵌入的断言越多,在执行期间(尤其是在模糊测试过程中)发现那些通用检查器无法捕捉的错误的机会就越大。如果您担心断言对性能的影响,请记住断言可以在生产代码中关闭(不过保留最关键的检查项通常是有益的)。
断言在发现错误时最重要的用途之一是检查复杂数据结构的完整性。让我们用一个简单示例来说明这个概念。假设我们有一个机场代码到机场名称的映射,如下所示:
airport_codes: Dict[str, str] = {
"YVR": "Vancouver",
"JFK": "New York-JFK",
"CDG": "Paris-Charles de Gaulle",
"CAI": "Cairo",
"LED": "St. Petersburg",
"PEK": "Beijing",
"HND": "Tokyo-Haneda",
"AKL": "Auckland"
} # plus many more
这份机场代码列表可能非常关键:如果其中任何代码存在拼写错误,都可能影响我们的应用程序。因此,我们引入一个检查列表一致性的函数。这种一致性条件被称为表示不变量,因此检查该条件的函数(或方法)通常命名为 repOK(),意为“表示状态正常“。
def code_repOK(code: str) -> bool:
assert len(code) == 3, "Airport code must have three characters: " + repr(code)
for c in code:
assert c.isalpha(), "Non-letter in airport code: " + repr(code)
assert c.isupper(), "Lowercase letter in airport code: " + repr(code)
return True
assert code_repOK("SEA")
def airport_codes_repOK():
for code in airport_codes:
assert code_repOK(code)
return True
with ExpectError():
assert airport_codes_repOK()
通过这样的检查,我们就能够直接的发现代码列表是否存在错误;当然,如果您想添加额外的代码,我们不应该直接操作列表,而是通过设置一个专门的元素添加功能:
def add_new_airport(code: str, city: str) -> None:
assert code_repOK(code)
airport_codes[code] = city
代码中嵌入的 repOK() 断言越多,能捕获的错误就越多——甚至是那些仅特定于您的领域和问题的错误。此外,这类断言还能记录您在编程时所做的假设,从而帮助其他程序员理解代码并预防错误。
作为最后一个示例,我们考虑一个相当复杂的数据结构——红黑树,它是一种自平衡的二叉搜索树。实现红黑树并不算太难,但即使对于有经验的程序员来说,确保其正确性也可能需要数小时。然而,一个 repOK() 方法既能记录所有假设,也能对它们进行验证:
class RedBlackTree:
def repOK(self):
assert self.rootHasNoParent()
assert self.rootIsBlack()
assert self.rootNodesHaveOnlyBlackChildren()
assert self.treeIsAcyclic()
assert self.parentsAreConsistent()
return True
def rootIsBlack(self):
if self.parent is None:
assert self.color == BLACK
return True
def add_element(self, elem):
assert self.repOK()
... # Add the element
assert self.repOK()
def delete_element(self, elem):
assert self.repOK()
... # Delete the element
assert self.repOK()
Static Code Checkers
repOK() 断言带来的许多好处,也可以通过使用静态类型检查器来实现。例如在 Python 中,只要正确声明参数类型,MyPy 静态检查器就能立即发现类型错误:
typed_airport_codes: Dict[str, str] = {
"YVR": "Vancouver", # etc
}
如果我们现在添加一个非字符串类型的键,例如
typed_airport_codes[1] = "First"
错误就会立即被 MyPy 捕获:
mypy airports.py
airports.py: error: Invalid index type "int" for "Dict[str, str]"; expected type "str"
然而,若要静态检查更高级的属性(例如机场代码必须由三个大写字母组成,或树结构必须无环),很快就会触及静态检查的极限。您的 repOK() 断言仍然不可或缺——最好能与优秀的测试生成器结合使用。
A Fuzzing Architecture
由于我们希望在本章后续部分复用某些内容,现在让我们以便于重用(尤其是便于扩展)的方式重新定义相关组件。为此,我们引入一系列类,将上述功能以可复用的形式封装起来。
Runner Classes
我们首先引入 Runner(运行器)的概念——即一个负责使用给定输入执行某个对象的对象。运行器通常是被测试的某个程序或函数,但我们也可以定义更简单的运行器。
让我们从运行器的基类开始。一个运行器本质上提供 run(input) 方法,用于将输入(字符串)传递给运行器。run() 返回一个二元组 (result, outcome)。其中,result 是运行器特定的值,提供运行的详细信息;outcome 则将结果分类为三种类型:
- Runner.PASS —— 测试通过,程序运行产生了正确的结果
- Runner.FAIL —— 测试失败,程序运行产生了错误的结果
- Runner.UNRESOLVED —— 测试既未通过又未失败,这种情况发生在程序无法运行时,例如输入无效
class Runner:
"""Base class for testing inputs."""
# Test outcomes
PASS = "PASS"
FAIL = "FAIL"
UNRESOLVED = "UNRESOLVED"
def __init__(self) -> None:
"""Initialize"""
pass
def run(self, inp: str) -> Any:
"""Run the runner with the given input"""
return (inp, Runner.UNRESOLVED)
作为基类,Runner 主要为构建更复杂的运行器提供接口。更具体地说,我们引入继承自该超类的子类,以便添加额外方法或重写继承的方法。
PrintRunner 就是这种子类的一个例子:它直接打印所有接收到的内容,并重写了继承的 run() 方法。这是许多场景中的默认运行器。
class PrintRunner(Runner):
"""Simple runner, printing the input."""
def run(self, inp) -> Any:
"""Print the given input"""
print(inp)
return (inp, Runner.UNRESOLVED)
p = PrintRunner()
(result, outcome) = p.run("Some input")
ProgramRunner 类则将输入发送到程序的标准输入。程序在创建 ProgramRunner 对象时指定。
class ProgramRunner(Runner):
"""Test a program with inputs."""
def __init__(self, program: Union[str, List[str]]) -> None:
"""Initialize.
`program` is a program spec as passed to `subprocess.run()`"""
self.program = program
def run_process(self, inp: str = "") -> subprocess.CompletedProcess:
"""Run the program with `inp` as input.
Return result of `subprocess.run()`."""
return subprocess.run(self.program,
input=inp,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True)
def run(self, inp: str = "") -> Tuple[subprocess.CompletedProcess, Outcome]:
"""Run the program with `inp` as input.
Return test outcome based on result of `subprocess.run()`."""
result = self.run_process(inp)
if result.returncode == 0:
outcome = self.PASS
elif result.returncode < 0:
outcome = self.FAIL
else:
outcome = self.UNRESOLVED
return (result, outcome)
cat = ProgramRunner(program="cat")
cat.run("hello")
下方是处理二进制(即非文本)输入和输出的一个变体。
class BinaryProgramRunner(ProgramRunner):
def run_process(self, inp: str = "") -> subprocess.CompletedProcess:
"""Run the program with `inp` as input.
Return result of `subprocess.run()`."""
return subprocess.run(self.program,
input=inp.encode(),
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
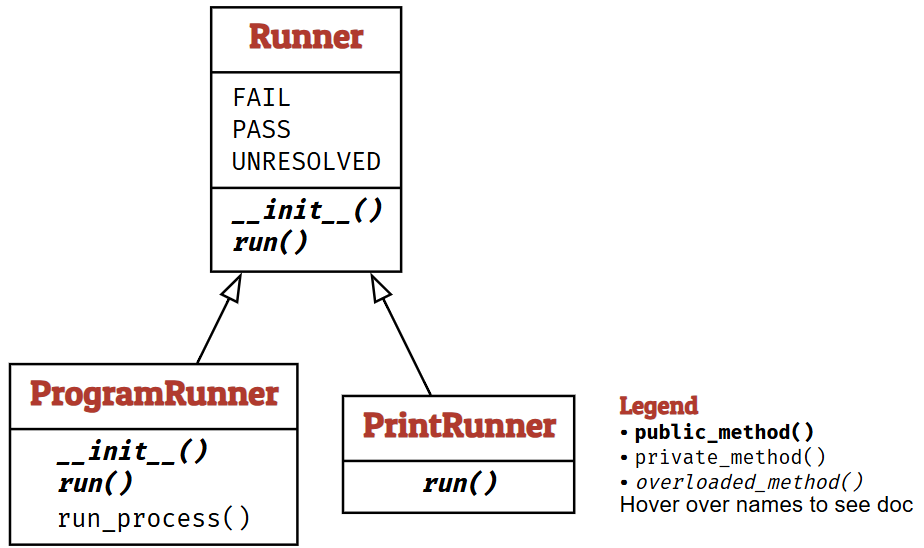
Fuzzer Classes
现在让我们定义一个能将数据实际馈送给消费者的模糊器。模糊器的基类提供一个关键方法 fuzz() 用于生成输入。run() 函数随后将 fuzz() 产生的输入发送给运行器并返回结果;runs() 则按给定次数重复执行此过程。
class Fuzzer:
"""Base class for fuzzers."""
def __init__(self) -> None:
"""Constructor"""
pass
def fuzz(self) -> str:
"""Return fuzz input"""
return ""
def run(self, runner: Runner = Runner()) \
-> Tuple[subprocess.CompletedProcess, Outcome]:
"""Run `runner` with fuzz input"""
return runner.run(self.fuzz())
def runs(self, runner: Runner = PrintRunner(), trials: int = 10) \
-> List[Tuple[subprocess.CompletedProcess, Outcome]]:
"""Run `runner` with fuzz input, `trials` times"""
return [self.run(runner) for i in range(trials)]
默认情况下,Fuzzer 对象功能有限,因为其 fuzz() 函数仅是一个抽象占位符。然而,子类 RandomFuzzer 实现了上文 fuzzer() 函数的功能,并增加了 min_length 参数以指定最小长度。
class RandomFuzzer(Fuzzer):
"""Produce random inputs."""
def __init__(self, min_length: int = 10, max_length: int = 100,
char_start: int = 32, char_range: int = 32) -> None:
"""Produce strings of `min_length` to `max_length` characters
in the range [`char_start`, `char_start` + `char_range`)"""
self.min_length = min_length
self.max_length = max_length
self.char_start = char_start
self.char_range = char_range
def fuzz(self) -> str:
string_length = random.randrange(self.min_length, self.max_length + 1)
out = ""
for i in range(0, string_length):
out += chr(random.randrange(self.char_start,
self.char_start + self.char_range))
return out
通过 RandomFuzzer,我们现在可以创建一个模糊器,其配置只需在创建时指定一次即可。
random_fuzzer = RandomFuzzer(min_length=20, max_length=20)
for i in range(10):
print(random_fuzzer.fuzz())
现在我们可以将这类生成的输入发送给之前定义的 cat 运行器,验证 cat 是否确实将其(经过模糊测试的)输入复制到输出。
for i in range(10):
inp = random_fuzzer.fuzz()
result, outcome = cat.run(inp)
assert result.stdout == inp
assert outcome == Runner.PASS
然而,将模糊器与运行器结合使用非常普遍,因此我们可以直接使用 Fuzzer 类提供的 run() 方法来实现这一目的:
random_fuzzer.run(cat)
使用 runs() 方法,我们可以重复多次模糊测试运行,并获取结果列表。
random_fuzzer.runs(cat, 10)
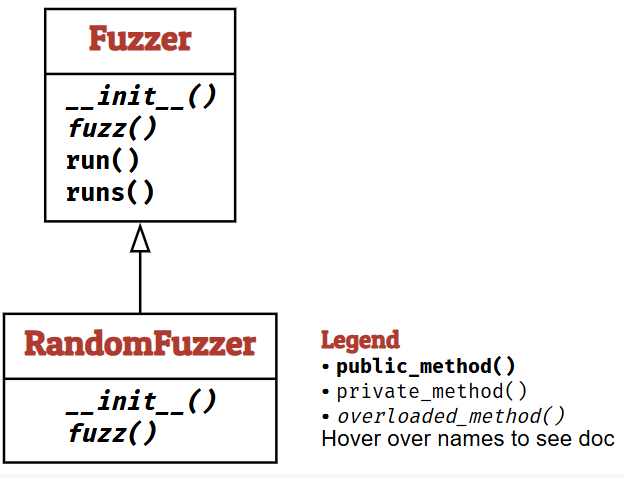
对于实际的代码文件,存放在 fuzz/book/codes 目录中。
至此,我们已经具备了创建模糊测试器的全部基础——从本章介绍的简单随机模糊测试器开始,甚至还能实现更高级的变体。敬请期待后续内容!
Code Coverage
在上一章中,我们介绍了基础模糊测试——即通过生成随机输入来测试程序。如何衡量这些测试的有效性?一种方法是检查发现错误的数量(及其严重性);但如果错误稀少,我们就需要一个替代指标来评估测试发现错误的可能性。本章将介绍代码覆盖率的概念,即测量测试运行期间程序实际被执行的部分。对于试图覆盖尽可能多代码的测试生成器而言,覆盖率测量也至关重要。
- 前置条件
- 你需要对程序的执行流程有一定的了解
- 完成上一章节的学习
A CGI Decoder
我们首先介绍一个简单的 Python 函数,该函数用于解码 CGI 编码字符串。CGI 编码常用于 URL(即网络地址)中,用于对 URL 中无效的字符(例如空格和某些标点符号)进行编码:
- 空格被替换为
+ - 其他无效字符被替换为
%xx,其中xx是两位十六进制等价值
因此,在 CGI 编码中,字符串 “Hello, world!” 会被转换为 “Hello%2c+world%21”。其中 2c 和 21 分别是逗号 (‘,’) 和感叹号 (‘!’) 的十六进制表示。
函数 cgi_decode() 的功能是接收经过此类编码的字符串,并将其解码还原为原始形式。我们的实现复现了Pezzè 等人,2008 年中的代码(该实现甚至包含了原代码中的缺陷——不过我们暂时不会在此处揭示它们)。
def cgi_decode(s: str) -> str:
"""Decode the CGI-encoded string `s`:
* replace '+' by ' '
* replace "%xx" by the character with hex number xx.
Return the decoded string. Raise `ValueError` for invalid inputs."""
# Mapping of hex digits to their integer values
hex_values = {
'0': 0, '1': 1, '2': 2, '3': 3, '4': 4,
'5': 5, '6': 6, '7': 7, '8': 8, '9': 9,
'a': 10, 'b': 11, 'c': 12, 'd': 13, 'e': 14, 'f': 15,
'A': 10, 'B': 11, 'C': 12, 'D': 13, 'E': 14, 'F': 15,
}
t = ""
i = 0
while i < len(s):
c = s[i]
if c == '+':
t += ' '
elif c == '%':
digit_high, digit_low = s[i + 1], s[i + 2]
i += 2
if digit_high in hex_values and digit_low in hex_values:
v = hex_values[digit_high] * 16 + hex_values[digit_low]
t += chr(v)
else:
raise ValueError("Invalid encoding")
else:
t += c
i += 1
return t
如果我们想要系统性地测试 cgi_decode() 函数,应该如何进行?测试领域文献中区分了两种推导测试用例的方法:黑盒测试与白盒测试。
Black-Box Testing
黑盒测试的核心思想是从功能规范中推导测试用例。就上述案例而言,我们需要根据明确定义的功能特性来测试 cgi_decode() 函数,包括:
- 测试
+的正确替换 - 测试
%xx的正确替换 - 测试不替换其他字符的情况
- 测试对非法输入的识别情况
assert cgi_decode('+') == ' '
assert cgi_decode('%20') == ' '
assert cgi_decode('abc') == 'abc'
try:
cgi_decode('%?a')
assert False
except ValueError:
pass
黑盒测试的优势在于能够发现与规范要求不符的行为偏差。由于它独立于具体实现,甚至可以在编码完成前就提前设计测试用例。但其局限性在于,实际代码的行为通常比规范描述更复杂,仅基于功能规格设计的测试往往无法覆盖所有实现细节。
White-Box Testing
与黑盒测试相反,白盒测试从代码实现(特别是内部结构)中推导测试用例。白盒测试与代码结构特征的覆盖概念紧密相关。例如,如果测试期间未执行某条代码语句,则意味着该语句中的错误也无法被触发。因此,白盒测试提出了一系列覆盖率标准,必须满足这些标准才能认为测试是充分的。最常用的覆盖率标准包括:
- 语句覆盖——代码中的每条语句必须被至少一个测试输入执行到。
- 分支覆盖——代码中的每个分支必须被至少一个测试输入执行到(这相当于要求每个 if 和 while 判断条件至少一次为真,一次为假)。
除此之外,还有更多覆盖率标准,包括已执行的分支序列、循环迭代次数(零次、一次、多次)、变量定义与使用之间的数据流等等;Pezzè等人,2008 年的著作对此有全面概述。
让我们以上文的 cgi_decode() 函数为例,思考如何确保代码中的每条语句至少被执行一次。我们需要覆盖以下情况:
- 条件判断 if c == ’+’对应的代码块
- 条件判断 if c == ’%’对应的两个分支(有效输入情况与无效输入情况)
- 处理其他字符的最终 else 情况
这导致了与前述黑盒测试相同的测试条件;上述断言确实能够覆盖代码中的每条语句。这种对应关系实际上相当常见,因为程序员倾向于在不同的代码位置实现不同功能,因此覆盖这些代码位置自然会生成覆盖不同(规范定义的)行为的测试用例。
白盒测试的优势在于能够发现已实现代码中的错误。即使在规格说明缺乏足够细节的情况下,它依然可以执行测试;实际上,它有助于识别(从而补充说明)规格说明中的边界情况。其缺点在于可能遗漏未实现的功能:如果某些规范要求的功能未被编码实现,白盒测试将无法发现这类缺失。
Tracing Executions
白盒测试的一个显著特点是能够自动评估程序功能是否被覆盖。为此,我们需要对程序执行进行插装——即在运行过程中通过特定机制追踪已执行的代码。测试结束后,这些信息可反馈给开发人员,使其能专注于为未覆盖的代码编写测试用例。
在大多数编程语言中,配置程序以追踪其执行过程相当困难。但 Python 则不然。通过 sys.settrace(f) 函数,我们可以定义一个追踪函数 f(),该函数会在每行代码执行时被调用。更强大的是,它能获取当前函数及其名称、当前变量内容等信息。因此,它成为动态分析(即对实际执行过程进行分析)的理想工具。
为了说明其工作原理,让我们再次观察 cgi_decode() 函数的一次具体执行过程。
cgi_decode("a+b")
为了追踪 cgi_decode() 函数的执行过程,我们将利用 sys.settrace() 方法。首先,我们需要定义一个会被每行代码调用的追踪函数。该函数包含三个参数:
- frame 参数用于获取当前执行帧,可访问当前位置和变量信息:
- frame.f_code 是当前执行的代码对象,frame.f_code.co_name 表示函数名;
- frame.f_lineno 记录当前行号;
- frame.f_locals 包含当前局部变量和参数。
- event 参数是描述事件类型的字符串,常见值包括“line“(执行到新行)或“call“(函数被调用)。
- arg 参数为某些事件提供附加信息,例如对于“return“事件,arg 包含返回值。
我们利用追踪函数来简单报告当前执行的代码行,该信息通过 frame 参数获取。
coverage = []
def traceit(frame: FrameType, event: str, arg: Any) -> Optional[Callable]:
"""Trace program execution. To be passed to sys.settrace()."""
if event == 'line':
global coverage
function_name = frame.f_code.co_name
lineno = frame.f_lineno
coverage.append(lineno)
return traceit
def cgi_decode_traced(s: str) -> List:
global coverage
coverage = []
sys.settrace(traceit) # Turn on
cgi_decode(s)
sys.settrace(None) # Turn off
coverage
详细的代码介绍在原文中有介绍,请参考 Tracing-Executions。此处不再着重介绍。
A Coverage Class
在这本书中,我们将反复利用覆盖率——来衡量不同测试生成技术的有效性,同时也引导测试生成朝着代码覆盖率的方向发展。我们之前的全局 coverage 变量实现在这方面有些繁琐。因此,我们实现了一些功能来帮助我们轻松测量覆盖率。
但是,我们主要关注于是如何使用该类进行覆盖率测试,因此也不再赘述其实现。
with Coverage() as cov:
function_to_be_traced()
c = cov.coverage()
Comparing Coverage
由于我们将覆盖率表示为一组执行的行,因此我们也可以对这些行应用集合运算。例如,我们可以找出哪些行被单个测试用例覆盖,而其他测试用例没有覆盖:
with Coverage() as cov_plus:
cgi_decode("a+b")
with Coverage() as cov_standard:
cgi_decode("abc")
cov_plus.coverage() - cov_standard.coverage()
输出的结果是仅在在 ‘a+b’ 输入中执行的行。我们还可以通过比较集合来确定哪些代码行仍需覆盖。定义 cov_max 为我们能实现的最大覆盖率。(这里,我们通过执行已有的“优质“测试用例来实现。实际操作中,人们会静态分析代码结构——这部分内容我们将在符号测试章节中介绍。)
with Coverage() as cov_max:
cgi_decode('+')
cgi_decode('%20')
cgi_decode('abc')
try:
cgi_decode('%?a')
except Exception:
pass
Coverage of Basic Fuzzing
现在我们可以利用覆盖率追踪来评估测试方法的有效性——尤其是测试生成方法的效果。我们的挑战在于:仅使用随机输入,就要让 cgi_decode() 函数达到最大覆盖率。从理论上说,只要我们最终生成了宇宙中所有可能的字符串,就必然能达到目标——但这个过程究竟需要多久呢?为此,让我们先对 cgi_decode() 进行一次模糊测试迭代。
sample = fuzzer()
with Coverage() as cov_fuzz:
try:
cgi_decode(sample)
except:
pass
cov_fuzz.coverage()
通过如下操作来检查是否到达最大覆盖率:
cov_max.coverage() - cov_fuzz.coverage()
让我们再尝试一次,通过 100 个随机输入来提高覆盖率。我们使用一个名为 cumulative_coverage 的数组来记录随时间推移所达到的覆盖率:cumulative_coverage[0]表示输入第 1 个样本后覆盖的代码行总数,cumulative_coverage[1]表示输入第 1 至第 2 个样本后覆盖的代码行数,依此类推。
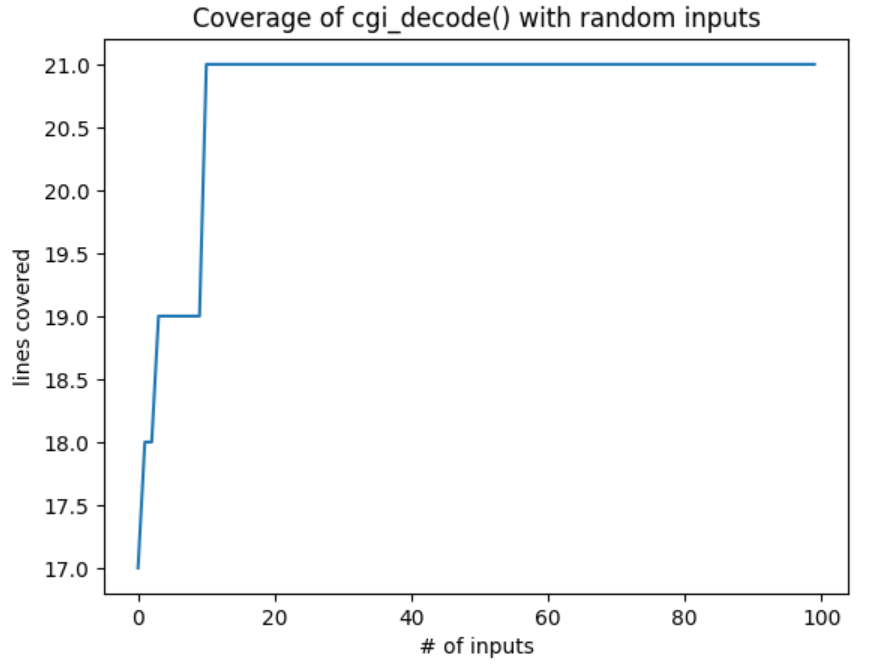
当然,上面的图表只是经过了一次测试后的结果,让我们进行多次重复并绘制平均值可以发现,在 40-60 个模糊测试输入后,我们获得了完整的覆盖率。
Finding Errors with Basic Fuzzing
只要有足够的时间,无论采用何种编程语言,我们确实能够覆盖 cgi_decode() 函数中的每一行代码。不过,这并不意味着代码就完全没有错误。由于我们并未检查 cgi_decode() 的返回结果,该函数可能返回任意值而不会被我们察觉或验证。要捕捉这类错误,就需要设置一个结果校验器(通常称为“预言机“)来验证测试结果。在我们的案例中,可以通过对比 C 语言和 Python 语言实现的 cgi_decode() 函数,检查两者是否产生相同的结果。
然而,模糊测试真正擅长的领域在于发现那些即使不检查结果也能检测到的内部错误。
Mutation-Based Fuzzing
大多数随机生成的输入在语法上是无效的,因此会被处理程序快速拒绝。为了测试输入处理之外的功能,我们必须提高获得有效输入的概率。其中一种方法是所谓的变异模糊测试——即对现有输入引入微小改动,这些改动可能仍保持输入的有效性,同时能触发新的程序行为。我们将展示如何创建这类变异,并如何引导它们覆盖尚未执行的代码区域,这一方法应用了流行模糊测试工具 AFL 的核心原理。
Fuzzing with Mutations
2013 年 11 月,美国模糊测试工具 American Fuzzy Lop(简称 AFL)首个版本正式发布。自问世以来,AFL 已成为最成功的模糊测试工具之一,并衍生出多个变种版本(例如 AFLFast、AFLGo 和 AFLSmart,本书将对这些变种进行讨论)。AFL 的推广使得模糊测试成为自动化漏洞检测的主流选择——它首次证明:在众多安全关键型实际应用中,漏洞可以被大规模自动检测出来。本章将介绍变异模糊测试的基础知识;
下一节将进一步阐述如何引导模糊测试针对特定代码目标。
Fuzzing a URL Parser
许多程序在处理输入数据前,都要求这些数据必须符合特定的格式要求。以 URL(网络地址)处理程序为例——只有当 URL 符合有效格式规范(即标准 URL 格式)时,程序才能正确解析。那么当我们使用随机输入进行模糊测试时,实际生成有效 URL 的概率有多大呢?
要深入理解这个问题,我们需要剖析 URL 的组成结构。一个完整的 URL 由多个要素构成:
scheme://netloc/path?query#fragment
其中:
- scheme(协议方案):指定要使用的通信协议,包括 http、https、ftp、file 等
- netloc(网络位置):表示要连接的主机名称,例如 www.google.com
- path(路径):指主机上的具体资源路径,例如 search
- query(查询参数):包含键值对参数列表,例如 q=fuzzing
- fragment(片段标识):用于标记所获取文档中的特定位置,例如 #result
urlparse("http://www.google.com/search?q=fuzzing")
ParseResult(scheme='http', netloc='www.google.com', path='/search', params='', query='q=fuzzing', fragment='')
我们看到,结果是如何将 URL 的各个部分编码到不同属性中的。
现在,让我们假设我们有一个程序,它以一个 URL 作为输入。为了简化问题,我们不会让它做太多事情;我们只是让它检查传入的 URL 是否有效。如果 URL 是有效的,它返回 True;否则,它会抛出一个异常。
def http_program(url: str) -> bool:
supported_schemes = ["http", "https"]
result = urlparse(url)
if result.scheme not in supported_schemes:
raise ValueError("Scheme must be one of " +
repr(supported_schemes))
if result.netloc == '':
raise ValueError("Host must be non-empty")
# Do something with the URL
return True
现在,让我们去对 http_program() 进行模糊测试(fuzz)。在进行模糊测试时,我们使用全部可打印的 ASCII 字符,这样便包括了冒号 (:)、斜杠 (/) 以及小写字母等字符。
fuzzer(char_start=32, char_range=96)
'"N&+slk%h\x7fyp5o\'@[3(rW*M5W]tMFPU4\\P@tz%[X?uo\\1?b4T;1bDeYtHx #UJ5w}pMmPodJM,_'
如果我们没有任何限制的随机进行 fuzz() 生成测试数据,实际上生成一个有效 URL 的概率有多大呢?我们需要我们的字符串以 “http://” 或 “https://” 开头。我们先来看 “http://” 的情况。这是七个非常特定的字符,我们必须从这七个字符开始。随机生成这七个字符的概率(在 96 个不同字符的范围内)是 \( 1:96^7 \),生成一个 “https://” 前缀的概率甚至更低,为 \( 1:96^8 \)。那么总的概率为:
\[ likelihood = \frac{1}{96^7} + \frac{1}{96^8} = 1.344627131107667e-14 \]
即使我们进行大量并行化处理,我们仍然需要等待数月甚至数年的时间。而这一切仅仅是为了获得一次成功的运行,从而让测试深入到 http_program() 的内部逻辑。
基本的模糊测试能够较好地测试 urlparse() 函数。如果这个解析函数中存在错误,那么模糊测试有较大的机会将其发现。但是,只要我们无法生成一个有效的输入(比如一个格式正确的 URL),我们就无法幸运地触及到程序中更深层次的功能逻辑。
Mutating Inputs
另一种方法不是完全从头开始生成随机字符串,而是从一个已知的合法输入入手,然后对其进行后续的变异操作。在这个上下文中,“变异”指的是一种简单的字符串操作——比如插入一个(随机的)字符、删除一个字符,或者修改某个字符表示中的一个比特位。这种方式被称为变异模糊测试(mutational fuzzing),与我们前面讨论过的生成式模糊测试(generational fuzzing)技术形成对比。
以下是一些你可以用来开始的变异操作示例:
def delete_random_character(s: str) -> str:
"""Returns s with a random character deleted"""
if s == "":
return s
pos = random.randint(0, len(s) - 1)
# print("Deleting", repr(s[pos]), "at", pos)
return s[:pos] + s[pos + 1:]
def insert_random_character(s: str) -> str:
"""Returns s with a random character inserted"""
pos = random.randint(0, len(s))
random_character = chr(random.randrange(32, 127))
# print("Inserting", repr(random_character), "at", pos)
return s[:pos] + random_character + s[pos:]
def flip_random_character(s):
"""Returns s with a random bit flipped in a random position"""
if s == "":
return s
pos = random.randint(0, len(s) - 1)
c = s[pos]
bit = 1 << random.randint(0, 6)
new_c = chr(ord(c) ^ bit)
# print("Flipping", bit, "in", repr(c) + ", giving", repr(new_c))
return s[:pos] + new_c + s[pos + 1:]
这样,我们就可以从上述操作中,获取到一系列合法的输入。
现在的思路是:如果我们手头已经有一些合法的输入,就可以通过对这些输入应用上述某种变异操作,来生成更多的候选输入。为了理解这一过程是如何运作的,让我们回到 URL 的例子上来。
Mutating URLs
现在,让我们回到 URL 解析的问题上来。我们来创建一个函数 is_valid_url(),用于检查 http_program() 是否接受某个输入(即判断该输入是否为一个有效的 URL)
def is_valid_url(url: str) -> bool:
try:
result = http_program(url)
return True
except ValueError:
return False
现在,让我们对一个给定的 URL 应用 mutate() 函数,并观察我们能获得多少个有效的输入。我们可以发现,通过对原始输入进行变异,我们得到了很高比例的有效输入。
那么,通过变异一个以 http: 开头的种子输入来生成一个以 https: 开头的输入,其概率有多大呢?我们需要插入一个正确的字符 ‘s’(从 96 个可打印字符中选中的概率为 \( 1:96 \)),并且把这个字符插入到正确的位置(概率为 \( 1:l \),其中 l 是输入的长度),同时还需要选择“插入”这个变异操作(假设选择该操作的概率为 \(1:3 \))。这意味着,平均而言,我们需要进行这么多次变异尝试,才能偶然生成一个包含 https:前缀的输入。
当然,如果我们想要生成一个比如 “ftp://” 这样的前缀,我们就需要进行更多的变异操作,也需要运行更多次尝试 —— 但最重要的是,我们需要应用多次变异,而不是一次简单的变异就能达到目标。
Multiple Mutations
到目前为止,我们只是在样本字符串上应用了一次单一的变异。然而,我们也可以应用多次变异,从而对字符串进行更大幅度的改动。例如,如果我们在一个样本字符串上应用 20 次变异,会发生什么呢?
0 mutations: 'http://www.google.com/search?q=fuzzing'
5 mutations: 'http:/L/www.googlej.com/seaRchq=fuz:ing'
10 mutations: 'http:/L/www.ggoWglej.com/seaRchqfu:in'
15 mutations: 'http:/L/wwggoWglej.com/seaR3hqf,u:in'
20 mutations: 'htt://wwggoVgle"j.som/seaR3hqf,u:in'
25 mutations: 'htt://fwggoVgle"j.som/eaRd3hqf,u^:in'
30 mutations: 'htv://>fwggoVgle"j.qom/ea0Rd3hqf,u^:i'
35 mutations: 'htv://>fwggozVle"Bj.qom/eapRd[3hqf,u^:i'
40 mutations: 'htv://>fwgeo6zTle"Bj.\'qom/eapRd[3hqf,tu^:i'
45 mutations: 'htv://>fwgeo]6zTle"BjM.\'qom/eaR[3hqf,tu^:i'
正如你所看到的,原始的种子输入几乎已经变得难以辨认了。通过对输入进行一次又一次的变异,我们获得了更加多样化的输入数据。
为了在单个工具或类中实现这样的多次变异,让我们引入一个名为 MutationFuzzer 的类。它接收一个种子(即一列字符串)作为输入,同时还可以设定变异的最小次数和最大次数。
接下来,我们将通过向 MutationFuzzer 类中添加更多方法来进一步扩展它的功能。在 Python 语言中,要求我们必须将一个类的所有方法定义在一个连续的代码块中,也就是说,整个类必须一次性完整地定义出来。
然而,我们更希望能够一个方法一个方法地介绍和讲解,而不是一次性把所有方法都写出来。为了解决这个问题,我们可以使用一个特殊的技巧(hack):每当我们想要向某个类 C 中添加一个新方法时,我们使用如下这种结构方式来实现。
class C(C):
def new_method(self, args):
pass
这看起来像是将 C 定义为了它自身的子类,这在逻辑上是说不通的 —— 但实际上,它所做的是:将一个新的类 C 定义为旧类 C 的子类,然后用这个新的类 覆盖(shadow)掉原来旧的 C 定义。
通过这种方式,我们最终得到的是一个包含了新方法 new_method() 的 C 类,而这正是我们想要的。(不过需要注意的是,之前已经创建的 C 类对象仍然基于旧的 C 定义,因此如果它们需要使用新方法,就必须重新构建。)
利用这个技巧,我们现在就可以添加一个 mutate() 方法,这个方法实际上会调用前面提到的那个 mutate() 函数。将 mutate() 实现为一个方法 是很有用的,尤其是当我们后续想要扩展 MutationFuzzer 类(比如增加更多功能或变异策略)时,这样我们就可以直接在类内部调用该方法,而不必每次都去调用外部的函数。
class MutationFuzzer(MutationFuzzer):
def mutate(self, inp: str) -> str:
return mutate(inp)
让我们回到我们的核心策略:尽可能提高种群(population)中输入的多样性,以扩大覆盖范围。
首先,我们来创建一个方法 create_candidate(),它的作用是:
- 从当前种群(也就是 self.population,即我们已经有的输入集合)中随机选取一个输入;
- 然后对这个输入应用介于 min_mutations 和 max_mutations 之间的若干次变异操作(mutation steps);
- 最终返回经过这些变异后得到的新输入。
换句话说,这个方法会基于现有的某个“种子”输入,通过多次随机变异,生成一个新的、可能有所不同的输入,从而为我们的测试输入池引入更多变化,提升测试的覆盖范围。
然而,输入的多样性越高,也就意味着其中出现无效输入(invalid input)的风险也越大。
要想成功,关键在于对这些变异进行引导(guiding these mutations) —— 也就是说,我们要保留那些特别有价值的变异结果。
Guiding by Coverage
为了尽可能覆盖更多的功能,我们可以依赖两种方式:一种是基于程序的明确规范(specified functionality),另一种是基于程序的实际实现(implemented functionality),正如我们在“覆盖率(Coverage)”那一章中所讨论的那样。不过,就目前而言,我们暂不假设程序的行为有明确的规范(尽管如果能有一个规范当然会更好)。但我们假设被测程序是存在的,而且我们可以利用程序本身的结构来指导测试用例的生成。
由于测试的过程本质上就是运行程序本身,因此我们总是可以获取到程序运行时的一些信息 —— 至少也能知道一个测试用例是通过(pass)还是失败(fail)。此外,由于覆盖率(coverage)也常常被用作衡量测试质量的一个指标,所以我们这里也假设我们能够获取每次测试运行所达到的覆盖率信息。
那么问题来了:我们如何利用这些覆盖率信息来指导测试用例的生成呢?
一个特别成功的思路,已经在广受欢迎的一款模糊测试工具中得到了实际应用,这款工具叫做 American Fuzzy Lop,通常简称为 AFL。
与上面我们讨论的例子类似,AFL 也会对那些“成功”的测试用例进行演化(进化) —— 但在 AFL 的语境中,“成功”指的是 发现了程序执行中的一条新路径(a new path through the program execution)。也就是说,AFL 会持续对那些已经发现过新执行路径的输入进行变异;而一旦某个输入又发现了另外一条新路径,那么这个输入也会被保留下来,作为后续变异的基础。参考AFL Technical
那么,接下来,我们就来构建这样一个策略。我们首先引入一个 Runner 类,它的作用是捕获某个函数在运行时的覆盖率信息。我们先从定义一个 FunctionRunner 类 开始:
http_runner = FunctionRunner(http_program)
http_runner.run("https://foo.bar/")
现在,我们可以对 FunctionRunner 类 进行扩展,使其也能够测量程序运行时的覆盖率。在执行完 run() 方法之后,我们可以通过调用 coverage() 方法,来获取上一次运行所达到的覆盖率信息。
现在,我们来看主类(核心类)的实现。在这个类中,我们会维护两个主要的东西:
- population(种群):也就是我们当前已经拥有的、用于测试的输入集合;
- coverages_seen(已见过的覆盖率集合):记录下我们在之前的测试中已经获得过的各种覆盖率情况,用来判断某次运行是否带来了新的覆盖路径。
此外,我们还定义了一个辅助函数 fuzz(),它的作用是:
- 接收一个输入(input);
- 使用给定的目标函数 function() 对该输入进行运行(调用);
- 然后检查这次运行所得到的 覆盖率(coverage) 是否是新的(即:是否尚未出现在 coverages_seen 集合中);
- 如果是新的覆盖率,那么就把这个输入加入到种群(population)中,同时把这次获得的覆盖率也加入到 coverages_seen 中,表示这个覆盖率已经被发现过了。
seed_input = "http://www.google.com/search?q=fuzzing"
mutation_fuzzer = MutationCoverageFuzzer(seed=[seed_input])
mutation_fuzzer.runs(http_runner, trials=10000)
mutation_fuzzer.population
通过这样的操作,能够使得每一个输入都是有效的,并且每一个输入都具有不同的覆盖率。这些输入是通过各种不同的组合产生的,包括:协议方案(schemes)、路径(paths)、查询参数(queries)以及片段(fragments)等不同部分的变异组合。
这个策略的一个优点是:当它被应用到更大的程序上时,它能够愉快地(即自动地、持续地)一条路径接着一条路径地进行探索 —— 从而一个功能接着一个功能地覆盖程序的各个部分。
而我们所需要做的,仅仅是找到一种方法来捕获程序运行时的覆盖率信息(coverage)。
Greybox Fuzzing
Search-Based Fuzzing
Mutation Analysis
Part Ⅲ: Syntactic Fuzzing
Fuzzing with Grammars
Efficient Grammar Fuzzing
Grammar Coverage
Parsing Inputs
Probabilistic Grammar Fuzzing
Fuzzing with Generators
Greybox Fuzzing with Grammars
Reducing Failure-Inducing Inputs
Part Ⅳ: Semantic Fuzzing
Fuzzing with Constraints
Mining Input Grammars
Tracing Information Flow
Concolic Fuzzing
Symbolic Fuzzing
Mining Function Specifications
Part Ⅴ: Domain-Specific Fuzzing
Testing Configurations
Fuzzing APIs
Carving Unit Tests
Testing Compilers
Testing Web Applications
Testing Graphical User Interfaces
Part Ⅵ: Managing Fuzzing
Fuzzing in the Large
When To Stop Fuzzing
AFL
AFL 的全称是 American Fuzzy Lop。这个名字源于一种宠物兔的品种,但在计算机安全领域指的是一个面向安全的模糊测试器。
简单来说,AFL 是一个用于自动发现软件中潜在漏洞(尤其是内存破坏类漏洞,如缓冲区溢出、释放后使用等)的强大工具。它通过向目标程序提供自动生成的、非预期的输入数据,并监视程序的异常行为(如崩溃、挂起)来工作。
AFL 的成功不在于它的复杂性,而在于它引入的一个非常巧妙的思路。在 AFL 之前,模糊测试大多是“盲目”的,比如随机生成数据。AFL 的核心创新在于“基于覆盖率的引导”。
不仅要测试程序,还要知道你的测试数据让程序执行了哪些新的代码路径。然后,优先选择那些能触发新路径的测试用例进行“变异”,从而像进化一样,让测试越来越深入程序的核心逻辑。
对于新入门计算机安全领域的读者来说,AFL 是一个不可多得的易上手的工具,整个项目代码不超过一万行。本章节主要介绍 AFL 的核心设计理念以及核心源码分析。
Historical
原文源自 Historical Notes。
本文讨论了 AFL(American Fuzzy Lop)一些高级设计决策的合理性。这些内容源自与 Rob Graham 的讨论。
Influence
简而言之,afl-fuzz 主要受到 Tavis Ormandy 在 2007 年所做工作的启发。Tavis 进行了一些极具说服力的实验,使用 gcov 块覆盖率从大量数据集中选择最优测试用例,并将这些测试用例作为传统模糊测试工作流程的起点。
所谓“有说服力“的意思是:捕获大量有趣的漏洞。
与此同时,AFL 的作者 (后面简称为 “我”) 和 Tavis 都对进化式模糊测试感兴趣。Tavis 有自己的实验,我而则在开发一个名为 bunny-the-fuzzer 的工具,该工具发布于 2007 年左右。
Bunny 使用了一种与 afl-fuzz 差异不大的代际算法,但也试图推理各种输入位与程序内部状态之间的关系,希望能从中获得一些额外价值。推理/关联部分可能部分受到了 Will Drewry 和 Chris Evans 在同一时期进行的其他项目的影响。
状态关联方法在理论上听起来非常诱人,但最终使模糊测试器变得复杂、脆弱且难以使用;每个其他目标程序都需要进行一些调整。由于 Bunny 的表现并不比更简单的暴力工具好多少,我最终决定放弃它。你仍然可以在以下链接找到它的原始文档:
https://code.google.com/p/bunny-the-fuzzer/wiki/BunnyDoc
在那时也有不少独立工作。最值得注意的是,在当年,Jared DeMott 有一个关于基于覆盖率的模糊器的 Defcon 演讲,该模糊器依赖于覆盖率作为适应度函数。
Jared 的方法与 afl-fuzz 的做法并不完全相同,但大体上属于同一范畴。他的模糊器试图通过单个输入文件明确求解最大覆盖率;相比之下,afl 只是选择那些能做新事情的情况(这能产生更好的结果——参见 Technical Details)。
几年后,Gabriel Campana 发布了 fuzzgrind,这是一个纯粹依赖 Valgrind 和约束求解器来最大化覆盖率而无需任何暴力搜索的工具;微软研究院的人则广泛讨论了他们尚未公开的、基于求解器的 SAGE 框架。
在过去六七年里,我也看到了不少关于智能模糊测试(主要关注符号执行)的学术论文,还有几篇讨论了遗传算法的概念验证应用,目标都是一致的。我并不认为这些实验大多有多实用;我怀疑其中许多受到了“bunny-the-fuzzer”诅咒的影响,在纸面上和精心设计的实验中看起来很酷,但在最终测试中却无法在经过良好模糊测试的真实世界软件中发现新的、有价值的漏洞。
在某些方面,“酷炫”解决方案需要与之竞争的基准比看起来要令人印象深刻得多,这使得竞争对手难以脱颖而出。以一个单一的例子来说,可以看看 Gynvael 和 Mateusz Jurczyk 的工作,他们将“笨拙”的模糊测试应用于 ffmpeg——现代浏览器和媒体播放器中一个重要且关键的组件:
http://googleonlinesecurity.blogspot.com/2014/01/ffmpeg-and-thousand-fixes.html
在同等复杂度的软件中,毫不费力地获得与最先进的符号执行相当的结果似乎仍然相当不可能,到目前为止在实践中也未被证明。
但我跑题了;归根结底,归因很难,而赞美 AFL 背后的基本概念可能是在浪费时间。关键往往在于那些常被忽视的细节,这带我们来到…
Design goals for afl-fuzz
简而言之,我认为当前的 afl-fuzz 实现解决了其他工具似乎无法解决的几个问题:
Speed
当你的“聪明“方案需要耗费大量资源时,想要靠蛮力取胜确实很难。如果你的检测手段能将发现漏洞的概率提高 10 倍,但运行速度却慢了 100 倍,那对用户来说就是亏本买卖。
为了避免一开始就处于劣势,afl-fuzz 的设计目的是让你以接近其原生速度的程度对大部分目标进行模糊测试——即使它没有增加价值,你也不会损失太多。
此外,该工具利用代码插装技术,通过多种方式实际减少工作量:例如,通过仔细修剪语料库或在输入文件中跳过非功能性但不可修剪的区域。
Rock-solid Reliability
如果你的方法脆弱且容易意外失败,就很难与“蛮力”竞争。自动化测试之所以有吸引力,是因为它简单易用且可扩展;任何违背这些原则的做法都是一种得不偿失的权衡,意味着你的工具会被更少使用,结果也会更不稳定。
目前 (作者当时),大多数基于符号执行、污点跟踪或复杂语法感知插桩的方法,在面对真实目标时都相当不可靠。更重要的是,它们的失败模式可能让它们比“笨办法”工具还要糟糕,而这种退化对于经验不足的用户来说往往难以察觉和纠正。
相比之下,afl-fuzz 的设计目标就是坚如磐石,主要方法就是保持简单。 实际上,它的核心就是一个非常优秀的传统模糊测试器,并采用了一系列经过深入研究、效果显著的策略。那些“高级”的部分,只是帮助它把精力集中在最重要的地方。
Simplicity
测试框架的作者,可能是唯一真正理解该工具所有设置项影响的人——也是唯一能精准调校这些参数的人。 然而,即便最基础的模糊测试框架,也往往附带无数需要操作者在测试前自行猜测的调节旋钮和模糊测试比例。这种设计往往弊大于利。
AFL 的设计目标正是尽可能避免这种情况。 你真正需要调整的只有三个参数:输出文件路径、内存限制,以及是否覆盖默认的自动校准超时设置。其余部分理应即开即用。如果出现问题,友好清晰的错误提示会直接指出可能原因和解决方案,让你迅速回到正轨。
Chainability
大多数通用模糊测试工具难以直接用于资源密集型或强交互型目标——要么得专门开发进程内定制化模糊器,要么就得投入巨额算力(其中大部分都浪费在与待测代码无关的任务上)。
AFL 则另辟蹊径:它允许用户针对轻量级目标(比如独立的图像解析库)生成精简的高价值测试用例集,这些用例后续既能接入人工测试流程,也能配合 UI 测试框架使用。
正如 Technical Details 中所述,AFL 的卓越表现并非源自对某个单一计算机科学理论体系的系统化应用,而是通过不断尝试各种小型、互补的技术方法——这些方法经实践验证能稳定产生超越随机猜测的成果。代码插桩只是这个工具箱中的一部分,但远非最重要的组成部分。
归根结底,关键在于 afl-fuzz 的设计初衷就是发现那些“酷炫“的漏洞,而且它确实有着相当可靠的实绩证明这一点。
Technical Detailed
本文简要概述了 American Fuzzy Lop 的核心机制。关于 AFL 背后的动机和设计目标,请参阅 Historical。
Design Statement
American Fuzzy Lop 努力避免专注于任何单一的操作原理 (singular principle of operation),也不作为任何特定理论的验证概念 (proof-of-concept, POC)。该工具可以被视为一系列经过实践测试、被发现出人意料地有效的技巧,并以当时我能想到的最简单、最稳健的方式实现。
许多最终的功能的实现得益于轻量级监控工具的可用性,该工具为该工具提供了基础,但应将此机制仅仅视为达到目的的手段。唯一真正的指导原则是速度、可靠性和易用性。
Coverage Measurements
通过注入到编译程序中的插桩代码会捕获分支(边)覆盖率以及粗略的分支执行命中次数。在分支点注入的代码本质上等价于:
cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
其中,cur_location 的值是在编译时随机生成的,这样做的目的是为了简化复杂项目的链接过程,并保证 XOR 输出结果的均匀分布。shared_mem[] 是一个由调用者传递给被插桩二进制程序的 64 KB 共享内存区域。输出映射中的每一个被设置的字节都可以看作是对某一个(分支源,分支目标)元组在插桩代码中的一次命中。
这里需要解释一个概念,格雷码
格雷码是一种二进制 numeral system,其中两个连续数值只有一个比特位的差异。这种特性被称为单位距离性(Unit Distance)。
上面的步骤实际上是在进行类似于计算两个连续编号的格雷码表示之间的差异。当控制流平滑地从一个基本块流向下一个时,这个差异值会很小,从而在 shared_mem 中产生局部性良好的访问模式。
//!!!! 这里需要一个详细解释,我暂时还没明白为什么这样能够表示一条路径
共享内存映射表(SHM)的大小经过精心选择,以确保在绝大多数目标程序中,哈希冲突是零星发生的;而这些目标程序通常包含 2000 到 10000 个可发现的分支点(branch points):
| Branch cnt | Colliding tuples | Example targets |
|---|---|---|
| 1,000 | 0.75% | giflib, lzo |
| 2,000 | 1.5% | zlib, tar, xz |
| 5,000 | 3.5% | libpng, libwebp |
| 10,000 | 7% | libxml |
| 20,000 | 14% | SQLlite |
| 50,000 | 30% | - |
与此同时,其数据量足够小,使得接收端能在微秒级时间内完成地图分析,并能轻松存入 L2 缓存。
这种覆盖率形式比简单的代码块覆盖能提供更深入的程序执行路径洞察。特别是,它能轻松区分以下两种执行轨迹:
A → B → C → D → E(Tuple:AB、BC、CD、DE)
A → B → D → C → E(Tuple:AB、BD、DC、CE)
这有助于发现底层代码中更隐蔽的故障条件,因为安全漏洞往往与意外或错误的状态转换相关 (一个 Tuple 就是一个新的状态转移),而不仅仅是到达新的基本块。
本节前面所示伪代码最后一行中进行移位操作的原因是为了保持元组的方向性(否则 A ^ B (A, B) 将与 B ^ A (B, A) 无法区分),并保留紧密循环的身份特征(否则 A ^ A 显然会等于 B ^ B)。
由于英特尔 CPU 上没有简单的饱和算术操作码,命中计数器有时可能会回绕到零。由于这是一个相当罕见且局部的事件,因此被视为可接受的性能权衡。
Detecting new Behaviors
模糊测试器(Fuzzer)会维护一个全局映射表,其中记录了以往测试执行过程中见过的元组(tuples)。当前测试产生的执行轨迹(trace)可以快速与该全局映射表进行比对和更新,此过程仅需几条双字(dword)或四字(qword)宽度的指令以及一个简单的循环即可完成。
当某个变异后的输入产生的执行轨迹包含了新的元组时,该输入文件会被保留下来,并交由后续的附加流程进行处理(详见Evolving the Input Queue)。反之,如果变异输入未能触发执行轨迹中出现新的局部状态转换(即没有产生新元组),即使其整体的控制流序列是唯一的,该输入也会被丢弃。
这种方法能够实现对程序状态进行非常精细且长期的探索,同时无需执行计算密集型且易出错的复杂执行轨迹全局对比,也避免了路径爆炸问题的困扰。
为了说明该算法的特性,请注意下面展示的第二条执行轨迹(#2)会被判定为具有显著新意,因为它包含了新的元组(CA, AE):
#1: A → B → C → D → E
#2: A → B → C → A → E
与此同时,在 #2 被处理之后,下面这条执行路径虽然整体控制流明显不同,却不会被识别为独特路径:
#3: A → B → C → A → B → C → A → B → C → D → E
这里做一个简单的解释
对于路径 #1 可以组成类似于这样的 Tuple:(A, B), (B, C), (C, D), (D, E)
对于路径 #2 而言,相较于 #1 的路径则多出了 (C, A),(A, E) 这两个 Tuple 对于路径 #3 而言,尽管路径比 #1 和 #2 看起来要更长更复杂,但实际上也只是 #1 和 #2 两种路径的组合罢了,没有新的状态产生,因此不会被全局状态所记录
除了检测新的元组(new tuples)外,模糊测试器(fuzzer)还会考虑粗粒度的元组命中计数(coarse tuple hit counts)。这些命中数被划分为几个桶(buckets):
命中计数:某个 Tuple 在测试过程中被执行了多少次就有多少次计数
有利于了解哪些代码路径经常被执行,哪些偶尔被触发
分桶策略有利于减少存储开销,也不会使得 fuzzer 过于敏感
1, 2, 3, 4-7, 8-15, 16-31, 32-127, 128+。
从某种程度上说,桶的数量是一种实现策略(implementation artifact):它允许将插桩(instrumentation)生成的 8 位计数器 (8-bit counter) 就地映射 (in-place mapping) 到模糊测试器可执行文件所依赖的一个 8 位置位图(8-position bitmap)上,以便跟踪每个元组已经出现过的执行次数。
通常,fuzzer 在插桩时会为每个 Tuple 维护一个八位计数器,用来统计命中次数,但是为了节省空间 & 提升效率,命中次数会映射到一个更小的桶索引,比如 0 ~ 7,每个索引代表了一个范围 (即上述的某个桶)
单个桶范围内的变化会被忽略;而从一个桶转换(transition)到另一个桶,则会被标记为程序控制流中一个值得关注的变化(interesting change),并被送往后面章节将要概述的进化过程 (evolutionary process) 进行处理。
命中计数机制提供了一种区分潜在有趣控制流变化的方法,例如,某个代码块从通常只执行一次变为执行了两次。与此同时,它对于经验上不太显著的变化相当不敏感,例如一个循环的周期数从 47 次变为 48 次。这些计数器还在密集的跟踪映射(trace maps)中,针对元组冲突(tuple collisions)提供了一定程度的“偶然”免疫力(“accidental” immunity)。
对于同一个元组而言,fuzzer 关注一个元组的确切的命中次数是过于敏感也无意义的,fuzzer 通常关注该元组的命中次数从一个桶范围跃迁到了另外一个桶,这意味着该代码块或者状态转换的执行频率显著上升,可能反映了程序逻辑的变化、新路径的触发、或隐藏行为的暴露
程序的执行受到内存和执行时间限制的严格监管(policed fairly heavily)。默认情况下,超时 (timeout) 设置为初始校准执行速度的 5 倍,并向上舍入到 20 毫秒。这种激进的超时设置(aggressive timeouts)旨在防止模糊测试器性能因陷入性能陷阱 (tarpits) 而急剧下降,例如,那种以速度降低 100 倍为代价换来覆盖率仅提高 1% 的情况;我们会务实(pragmatically)地拒绝这类情况,并期望模糊测试器能找到一种成本更低的方式来实现相同的代码覆盖。实证测试(Empirical testing)强烈表明,设置更宽松(more generous)的超时限制并不值得。
Evolving the input queue
那些产生了程序内新状态转换的变异测试用例会被加入到输入队列中,并作为未来几轮模糊测试的起点。它们是对已有发现的补充,但不会自动替换掉已有的测试用例。
也就是说,某个变异的输入触发了新的状态转移 (即新的元组),或者引起了某些代码块执行频率的桶迁移,那么这个输入就是有价值的,会被加入到输入队列中,成为下一轮模糊测试的种子输入。
与更为“贪婪”的遗传算法相比,这种方法使得工具能够逐步探索底层数据格式的各种互不关联、甚至可能相互不兼容的特征。如下图所示:
http://lcamtuf.coredump.cx/afl/afl_gzip.png

关于此算法成果的一些实际案例,在这里有详细讨论:
- http://lcamtuf.blogspot.com/2014/11/pulling-jpegs-out-of-thin-air.html
- http://lcamtuf.blogspot.com/2014/11/afl-fuzz-nobody-expects-cdata-sections.html
此过程产生的合成语料库,本质上是一个紧凑的、由那些有用的 (“嗯,这个能产生新行为!”) 的输入文件构成的集合。它可用于为后续的任何其他测试流程提供初始种子(例如,用于手动对资源密集型的桌面应用程序进行压力测试)。
通过上面的更新策略,AFL 在测试过程中会积累一个高质量的输入队列,里面每个输入 (文件) 都做过贡献——至少触发过一些新的状态迁移
采用这种基于覆盖引导的模糊测试方法,大多数测试目标的输入队列会增长到 1,000 到 10,000 个条目。其中,大约 10% 到 30% 的新条目是由于发现了全新的代码执行路径(即“新元组“),而其余的条目则与代码块的执行次数变化(即“命中计数“变化)有关。
下面的表格对比了几种不同的引导式模糊测试方法在发现文件语法结构和探索程序状态方面的相对能力。测试对象是使用 -O3 优化选项编译的 GNU patch 2.7.3,并初始使用一个虚拟文本文件作为种子输入。测试过程包括对输入队列进行单次遍历
| Fuzzer guidance | Blocks | Edges | Edge hit | Highest-coverage |
|---|---|---|---|---|
| strategy used | reached | reached | cnt var | test case generated |
| (Initial file) | 156 | 163 | 1.00 | (none) |
| Blind fuzzing S | 182 | 205 | 2.23 | First 2 B of RCS diff |
| Blind fuzzing L | 228 | 265 | 2.23 | First 4 B of -c mode diff |
| Block coverage | 855 | 1,130 | 1.57 | Almost-valid RCS diff |
| Edge coverage | 1,452 | 2,070 | 2.18 | One-chunk -c mode diff |
| AFL model | 1,765 | 2,597 | 4.99 | Four-chunk -c mode diff |
表格中,盲模糊测试(Blind fuzzing S)的第一项数据对应的是仅执行单轮测试的结果;第二组数据(Blind fuzzing L)则展示了模糊测试器在循环运行多个测试周期后的表现,其执行周期数与基于插桩的测试运行大致相当(后者因需要处理不断增长的输入队列而花费了更多时间)。
与盲模糊测试 (即完全随机变异,无任何引导的测试) 相比,AFL 模型的表现是更佳的,这证明了引导式模糊测试的方法更优
在另一项独立实验中获得了大致相似的结果。该实验对模糊测试器进行了修改,移除了所有随机模糊测试阶段,只保留了一系列基础的、顺序执行的操作,例如逐位翻转。由于这种模式无法改变输入文件的大小,因此实验使用了一个有效的统一差异格式文件作为初始种子输入。
| Queue extension | Blocks | Edges | Edge hit | Number of unique |
|---|---|---|---|---|
| strategy used | reached | reached | cnt var | crashes found |
| (Initial file) | 624 | 717 | 1.00 | - |
| Blind fuzzing | 1,101 | 1,409 | 1.60 | 0 |
| Block coverage | 1,255 | 1,649 | 1.48 | 0 |
| Edge coverage | 1,259 | 1,734 | 1.72 | 0 |
| AFL model | 1,452 | 2,040 | 3.16 | 1 |
如之前所指出的,遗传模糊测试的一些早期研究工作依赖于维护单个测试用例,并通过演化该用例来最大化覆盖率。至少在上述描述的测试中,这种“贪婪”的方法似乎并未比盲目的模糊测试策略带来显著优势。
移出了随机变异和遗传选择阶段,只使用基本的变异策略;在这种极度简化、非随机的设定下,AFL 模型的引导策略 (基于覆盖于命中技术) 仍然优于其他策略。
Culling the corpus
上述概述的渐进式状态探索方法意味着,在测试过程中后期合成的部分测试用例,其边缘覆盖率可能是其祖先测试用例所提供的覆盖率的严格超集。
在 AFL 中,变异所产生的新的状态会进入到输入队列,这样会使得某些后期生成的测试用例可能是早期用例的基础上多次变异而来,它们可能覆盖了祖先用例所覆盖的所有边,还额外覆盖了新的边;即边缘覆盖是祖先的严格超集
为了优化模糊测试的效率,AFL 会使用一种快速算法周期性地重新评估队列。该算法会从队列中筛选出一个更小的测试用例子集,这个子集必须能够覆盖到目前为止所有已观测到的元组,并且这些测试用例的特性使它们对工具而言特别有利。
因此,AFL 会尝试构建一个“优选测试用例子集”(optimized/canonical corpus),其满足:
- 覆盖全面性
- 高效性
该算法的具体工作原理是:根据每个队列条目的执行延迟和文件大小为其分配一个分数;然后,为每个元组选出得分最低的候选条目。
然后使用简单的流程顺序处理这些元组:
- 找到下一个尚未在临时工作集中的元组,
- 定位与此元组对应的优胜队列条目,
- 将该条目追踪信息中出现的所有元组注册到工作集中,
- 如果集合中仍有缺失的元组,则回到第 1 步。
为每个元组的测试用例挑选出触发它自身代价最小 (执行时间/文件大小) 的最低的测试用例作为该元组的最优测试用例
如果该元组尚未被覆盖,那么找到能触发该元组、且得分最低的测试用例作为其最优测试用例,加入到最优测试组中
直到该最优测试组中的测试用例能够覆盖所有元组,才会结束筛选
由此生成的“优选”条目语料库,其大小通常比初始数据集小 5 到 10 倍。非优选条目不会被丢弃,但当在队列中遇到它们时,会以不同的概率被跳过:
- 如果队列中存在尚未进行模糊测试的新的优选条目,那么 99% 的非优选条目会被跳过,以优先处理优选条目。
- 如果没有新的优选条目:
- 如果当前的非优选条目之前已经过模糊测试,则 95% 的情况下会被跳过。
- 如果它尚未经过任何模糊测试轮次,则跳过的概率会降至 75%。
根据经验性测试,这种机制在队列循环速度和测试用例多样性之间取得了合理的平衡。
对于输入或输出语料库,可以使用 afl-cmin 工具执行更精细但速度也慢得多的筛选。该工具会永久丢弃冗余条目,并生成一个更小的语料库,适用于 afl-fuzz 或外部工具。
Trimming input files
文件大小对模糊测试性能有显著影响。这既是因为大文件会降低目标二进制文件的运行速度,也是因为它们会降低变异操作触碰到重要格式控制结构(而非冗余数据块)的概率。更多细节在 perf_tips.txt 中有详细讨论。
即使用户可能提供低质量的初始语料库,某些类型的变异仍会逐步增大生成文件的体积,因此有必要抑制这种趋势。幸运的是,插桩反馈机制提供了一种自动精简输入文件的简单方法,同时能确保文件改动不会影响执行路径。
大文件既拖慢速度,又降低测试效率,所以应该尽量减小输入文件的大小,但要保证它仍然能触发相同的程序行为。
afl-fuzz 内置的修剪器会尝试以可变长度和步进依次删除数据块:任何不会改变轨迹映射校验和的删除操作都会同步到磁盘。该修剪器并非追求极致彻底,而是力求在精度与 execve() 调用次数之间取得平衡,并据此选择合适的块大小和步进值。平均每文件可缩减约 5-20% 的体积。
afl-fuzz 会以不同的块大小和步长,尝试删除输入文件中的数据库。如果删除后的执行路径未发生变化,则该块数据就是冗余的,可以安全删除
独立的 afl-tmin 工具采用更彻底的迭代算法,并额外尝试对修剪后的文件进行字母表归一化处理。其运行逻辑如下:
首先工具自动选择运行模式。若初始输入会导致目标程序崩溃,afl-tmin 将以非插桩模式运行,仅保留能生成更简洁文件且仍可触发崩溃的调整;若目标程序运行正常,则采用插桩模式,仅保留能产生完全一致执行路径的调整。
实际的最小化算法如下:
- 首先尝试以大步长对数据大块进行归零操作。实践证明,此举可通过预先替代后续细粒度操作来减少执行次数。
- 采用二分搜索式的策略,以递减的块大小和步长执行块删除操作。
- 通过统计唯一字符数量,尝试将每个字符批量替换为零值,实现字母表归一化。
- 最终对非零字节执行逐字节归一化处理。
afl-tmin 使用 ASCII 数字’0’而非 0x00 字节进行归零操作。这是因为这种修改更不容易干扰文本解析,从而更有利于文本文件的最小化处理。
相比学术研究中提出的其他测试用例最小化方法,本算法虽然复杂度较低,但所需执行次数大幅减少,且在多数实际应用中能产生相当的效果。
Fuzzing strategies
插桩反馈机制便于评估各类模糊测试策略的价值并优化其参数,使其能广泛适用于多种文件格式。afl-fuzz 采用的策略通常与具体格式无关,详细讨论可见:
http://lcamtuf.blogspot.com/2014/08/binary-fuzzing-strategies-what-works.html
值得注意的是,尤其在初始阶段,afl-fuzz 的大部分操作实际上是高度确定性的,直到后期才转向随机组合修改与测试用例拼接。确定性策略包括:
- 采用不同长度与步进的顺序位翻转
- 小整数的顺序加减操作
- 顺序插入已知特殊整数(如 0、1、INT_MAX 等)
采用确定性步骤开局的目的在于,其易于产生紧凑的测试用例,并能在非崩溃输入与崩溃输入间生成较小差异。
完成确定性模糊测试后,非确定性步骤包括组合位翻转、插入、删除、算术运算及不同测试用例的拼接。所有这些策略的相对收益与 execve() 成本已在上述博客文章中进行分析。
基于 Historical 中讨论的原因(主要是性能、简洁性与可靠性),AFL 通常不探究特定变异与程序状态间的关联关系;模糊测试步骤在名义上是盲目的,仅由输入队列的进化设计引导。
但存在一个(简单的)例外:当新队列条目经历初始确定性模糊测试步骤时,若观察到文件某些区域的修改对执行路径校验和没有影响,这些区域将在后续确定性阶段被排除——模糊测试器可直接进入随机变异阶段。尤其对于冗长的人类可读数据格式,此举可将执行次数减少 10-40% 左右,且不会明显影响覆盖率。极端情况下(如按块对齐的 tar 归档文件),收益可达 90%。
由于底层的“效应图“仅作用于单个队列条目,且仅在保持文件大小与整体结构不变的确定性阶段有效,该机制运行稳定且实现简洁。
Dictionaries
插桩反馈机制能自动识别某些输入文件中的语法标记,并检测预定义或自动发现的字典术语组合是否构成被测解析器的有效语法。关于这些功能在 afl-fuzz 中的实现原理可参阅:
http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html
本质上,当基础语法标记(通常易于获取)以纯随机方式组合时,插桩反馈与队列的进化设计共同构成一种区分机制:既能识别无意义的变异,也能发现触发插桩代码新行为的变异,并基于此逐步构建更复杂的语法结构。
实践表明,字典机制能使模糊测试器快速重构 JavaScript、SQL 或 XML 等复杂语言的语法规则。上述博客中展示了多个自动生成的 SQL 语句实例。
值得注意的是,AFL 的插桩机制还支持自动提取输入文件中已有的语法标记。其原理是检测字节序列中那些在翻转时能持续改变程序执行路径的片段——这暗示代码中存在与预定义值进行原子比较的逻辑。模糊测试器利用该信号构建精简的“自动字典“,并与其他模糊测试策略协同工作。
在一些半结构化输入文件中,通常具有一些具有特殊含义的固定字符串或字符序列;AFL 虽然无法理解这些含义,但在文件执行时,AFL 能够发现正确的“语句”能够使得执行路径发生显著变化,因此 AFL 就可能会将该语句打上标记,并以此进行变异。
也就是说,AFL 维护的输入队列,里面保存了历史中表现良好的输入,每次测试 AFL 从中挑选出输入,并在这基础上做小幅度、可控的变异
因此,有效的输入结构会被保留并逐步优化、扩展
De-duping crashes
崩溃去重是优秀模糊测试工具需要解决的关键问题之一。许多简单方案存在缺陷:例如,若崩溃发生在通用库函数(如 strcmp、strcpy)中,仅依据故障地址进行分类可能导致完全不相关的问题被归为一类;而通过校验调用栈回溯进行判重时,若故障可通过多条不同(甚至递归)路径触发,则会导致崩溃数量虚增。
afl-fuzz 采用的解决方案满足以下任一条件即判定为独立崩溃:
- 崩溃轨迹包含此前所有崩溃中未出现的新元组
- 崩溃轨迹缺失了早期故障中始终存在的元组
该方法在初期可能产生路径计数膨胀,但会表现出强烈的自限效应,这与作为 afl-fuzz 基石的执行路径分析逻辑具有相似性。
很多不同的输入可能会导致程序在 相同代码缺陷处崩溃,也有可能不同的代码缺陷发生在 相似的执行路径上,甚至可能因为调用栈的多样性(比如多条路径都能触发同一个 bug),而导致看似不同的崩溃其实本质相同。
- 新崩溃的轨迹中出现了之前所有崩溃都未曾出现的新元组(新的分支路径)
- 新崩溃的轨迹中缺失了之前所有崩溃中都存在的某个元组(某个关键分支不见了)
Investigating crashes
许多崩溃的可利用性存在模糊性。afl-fuzz 通过崩溃探索模式应对该问题:该模式下,已知触发故障的测试用例会以近似正常模糊测试的方式被变异,但附加了丢弃所有非崩溃变异的约束条件。此方法的价值详见于:
什么叫做模糊性?不是所有崩溃都“看起来”一样,也不是所有崩溃都容易判断其严重性,有些崩溃:
可能只是在特定边界条件下触发的无害异常; 也可能是由于测试输入本身的畸形所导致,与程序核心逻辑无关;
但也有可能是 严重的安全漏洞(比如 RCE、任意代码执行等)的表象。
http://lcamtuf.blogspot.com/2014/11/afl-fuzz-crash-exploration-mode.html
该方法利用插桩反馈探索崩溃程序状态,突破模糊的故障条件,并分离出新发现的输入供人工分析。关于崩溃处理需特别注意:与常规队列条目不同,崩溃输入不会被自动修剪,而是保持原始状态以便与队列中父级非崩溃条目进行对比。当然,用户可随时使用 afl-tmin 工具对其进行精简。
此时,输入不是从普通种子输入开始,而是从已经能够稳定触发目标程序崩溃的输入文件开始
AFL 会对这些崩溃输入做各种编译操作,保留仍能触发崩溃的变异
The fork server
为提升性能,afl-fuzz 采用“fork server“模式:被测试进程仅需经历一次 execve()、链接和 libc 初始化过程,随后即可通过写时复制机制从暂停的进程镜像进行克隆。具体实现详见:
http://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html
fork server 是植入式插桩的重要组成部分,它会在首个被插桩函数处暂停,等待 afl-fuzz 的指令。对于快速执行的目标,分支服务器可带来 1.5 倍至 2 倍的显著性能提升。此外还支持以下模式:
- 手动(“延迟 (deferred)”)模式:跳过用户指定的大段初始化代码。仅需对目标程序进行少量代码修改,某些场景下可实现 10 倍以上的性能提升。
- “持久化“模式:单个进程可测试多个输入,大幅降低重复 fork() 调用的开销。此模式通常需要对目标程序进行代码改造,但能使快速目标的性能提升 5 倍以上——在保持模糊测试进程与目标二进制文件强隔离的同时,获得近似进程内模糊测试的效能。
Parallelization
并行化机制通过定期检查其他 CPU 核心或远程机器上独立运行实例产生的队列,选择性地引入那些在本地测试时能产生当前模糊测试器未见过行为的测试用例。
该设计使模糊测试配置具有高度灵活性,例如可针对同一数据格式的不同解析器运行同步实例,往往能产生协同效应。更多设计细节请参阅 parallel_fuzzing.txt 文档。
Binary-only instrumentation
对黑盒二进制目标进行插桩是通过独立构建的 QEMU“用户模式仿真“实现的,该方案还支持跨架构代码执行(例如在 x86 平台运行 ARM 二进制文件)。
QEMU 以基本块为翻译单元,插桩机制在此基础上实现,其模型与编译时钩子类似:
if (block_address > elf_text_start && block_address < elf_text_end) {
cur_location = (block_address >> 4) ^ (block_address << 8);
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
}
第二行基于移位和异或的混淆操作用于消除指令对齐的影响。
QEMU、DynamoRIO 和 PIN 等二进制翻译器启动速度较慢。为此,QEMU 模式采用了与编译器插桩代码类似的分支服务器方案,直接复制已初始化并在 _start 处暂停的进程镜像。
新基本块的首次翻译也会产生较大延迟。为解决此问题,AFL 分支服务器通过在运行模拟器与父进程间建立通信通道,将新遇到的基本块地址加入翻译缓存,供后续子进程复用。
这两项优化使 QEMU 模式的开销降至约 2-5 倍,而 PIN 方案的开销通常超过 100 倍。
The afl-analyze tool
文件格式分析器是前述最小化算法的简单扩展。该工具不试图删除无效块,而是通过逐字节翻转操作对输入文件的字节序列进行标注分类:
- 无效块 (No-op blocks):位翻转不会引起控制流明显变化的区域。常见案例如注释段、位图文件中的像素数据等。
- 表层内容 (Superficial content):部分位翻转会引起控制流变化的区域。例如富文档(XML、RTF 等)中的字符串。
- 关键数据流 (Critical stream):所有位翻转都会以相关但不同的方式改变控制流的字节序列。可能是压缩数据、非原子比较的关键词或魔术值等。
- 疑似长度字段 (Suspected length field):任何修改都会导致程序控制流发生一致性变化的小型原子整数,通常暗示长度校验失败。
- 疑似校验和或魔术整数 (Suspected cksum or magic int):行为类似长度字段,但数值特征不符合长度定义。可能为校验和或其他“魔术“整数。
- 疑似校验块 (Suspected checksummed block):任何修改总是触发相同新执行路径的长数据块。通常因在校验或完整性检查失败导致后续解析中止。
- 魔术值区段 (Magic value section):引起前述二进制行为但不符合其他分类的通用标记。可能是原子比较的关键词等。
Hardware Security
计算机系统的安全领域正在经历一场从软件层面深入到硬件架构层面的变革。硬件安全(Hardware Security)已成为保障现代计算环境可靠性的关键支柱。本章将深入探讨不同处理器架构(尤其是 Arm 和 RISC-V)中那些巧妙且创新的硬件安全设计,这些设计旨在根本上消除或大幅缓解传统软件漏洞,如缓冲区溢出、代码重用攻击等。
我们将主要致力于讲解以下几个关键的硬件安全技术:
ARM
ARM 在其架构中不断引入硬件安全特性,以应对日益复杂的软件漏洞和安全威胁,特别是内存安全漏洞(如缓冲区溢出和释放后使用)。本节主要讲解 ARM 中的硬件安全设计原理:
- ARM PAC:主要针对控制流完整性 (Control-Flow Integrity, CFI) 漏洞,例如返回导向编程 (ROP) 和跳转导向编程 (JOP) 攻击。这些攻击通过篡改栈上的返回地址或函数指针来劫持程序的执行流程。
- ARM MTE:主要针对内存安全违规 (Memory Safety Violations),包括空间安全 (Spatial Safety)(如缓冲区溢出)和时间安全 (Temporal Safety)(如释放后使用 Use-After-Free)。
Pointer Authentication Code
概念预览
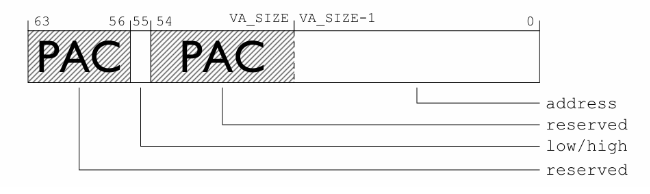
ARMv8.3-A 架构中引入了一种新特性,该特性使得寄存器内容被用作间接分支或数据引用的地址前对其进行认证。该特性利用了一个 64 位地址值中的最高位字节地址,将其作为指针认证码 (Pointer Authentication Code, PAC)。并且,根据该特性引入了对应的指令集。
int foo(int a, int b) {
return a + b;
}
int main() {
foo(1, 2);
return 0;
}
foo:
hint #34
sub sp, sp, #16
str w0, [sp, #12]
str w1, [sp, #8]
ldr w8, [sp, #12]
ldr w9, [sp, #8]
add w0, w8, w9
add sp, sp, #16
ret
main:
paciasp
sub sp, sp, #32
stp x29, x30, [sp, #16]
add x29, sp, #16
mov w8, wzr
str w8, [sp, #8]
stur wzr, [x29, #-4]
mov w0, #1
mov w1, #2
bl foo
ldr w0, [sp, #8]
ldp x29, x30, [sp, #16]
add sp, sp, #32
retaa
这是一个经典的示例 (点击这里打开),在 main 函数中,使用了 paciasp 在压栈保存时对 sp 指针进行签名。
Introduce
目前计算机攻击种类繁多,比较经典的就是利用 Gadgets (攻击者在目标链接程序或库中找到一系列由 *ret* 指令结尾的短指令序列) 进行攻击的 Return-Orientated-Programming (ROP) 和 Jump-Orientated-Programming (JOP)。
这里简要讲解一下 ROP 和 JOP 技术。
- ROP:ROP 不再手动注入
shellcode,而是通过劫持并扫描代码中的类似于ret语句,通过精心构建出预期想要执行的代码片段。- 例如:ROP 想要执行
system("/bin/sh"),那么就会扫描代码,并找出对应的代码片段组成如下:- STACK 8: “/bin/sh” -> 这里假设是一个
pop eax; ret语句,eax的值为/bin/sh - STACK 7: “mov ebx, eax; ret” -> 假设这里是第一个
gadgets的返回地址处,这里将 “/bin/sh” 存放到合适的寄存器中 - STACK 6: …. -> 假设经过了多个
gadgets继续配置需要的参数 - STACK N: “#system” -> 最终,有一个
gadgets返回的地址是system调用的地址,而前面已经将system的参数准备到寄存器中了。
- STACK 8: “/bin/sh” -> 这里假设是一个
- 至此,ROP 程序就找到了一个由
gadgets集合组成的调用链,通过这一个调用链,就可以无需插入任何shellcode就能够实现劫持代码并执行。
- 例如:ROP 想要执行
- JOP:JOP 是 ROP 攻击的一个变种,为了解决 ROP 防御手段而演变的一种攻击,其不再依赖
ret语句,而是通过类似于jmp eax语句来组成链式执行。并且为 JOP 实现了一个分发器,记录下每一个gadgets的内存地址,并按照制定顺序进行跳转形成链式执行。
为了抵御上述类型的攻击,ArmV8.3-A 引入了 PAC(Pointer Authentication Code) 特性使得攻击者在未被检测到的情况下更难修改内存中的受保护指针。
原理
现代计算机通常启用了 64 位架构,但实际使用中,地址空间又常常小于 64 位,例如:
- X86-64:通常只使用 48 位 或 52 位的有效虚拟地址空间
- ARM64:定义了多种虚拟地址空间大小,通常使用 48 位地址
- RISCV64:定义了多种虚拟地址空间大小,通常使用 39 位地址
因此,一个 64 位的指针,在实际使用中其高 8 位甚至更多位实际上并没有被用来存储地址信息,而是被标识 Reserve。ARM 所设计的 PAC 特性就是将这些没有利用起来的未使用高位利用起来,放置一个指针验证码 (PAC)。
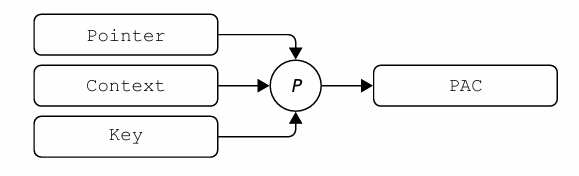
PA (Pointer Authentication) 使用指针的高位来存储 PAC 信息,该信息本质是使用指针值和一些上下文进行的加密签名:
在程序中,并非每种指针都有相同的用途。我们希望指针仅在特定的上下文中有效。在指针认证中,这通过两种方式实现:为主要用例使用单独的密钥,并通过对指针和 64 位上下文计算 PAC 来实现。
指针认证规范定义了五个密钥:两个用于指令指针,两个用于数据指针,以及一个用于在更长的数据序列上计算 MAC 的单独通用指令。指令编码确定使用哪个密钥。上下文对于隔离与同一密钥一起使用的不同类型的指针非常有用。在计算和验证 PAC 时,上下文被指定为附加参数,与指针一起使用。
\[
API\{A, B\} Key, APD\{A, B\} Key, APGAKey
\]
- Code Address: API{A, B}Key
- Data Address: APD{A, B}Key
- General Address: APGAKey
PAC 通过 \( Val_{pointer} + Context_{64bit} + Secret_{128 bit key} = PAC \) 组合,实现了上下文相关的指针认证:
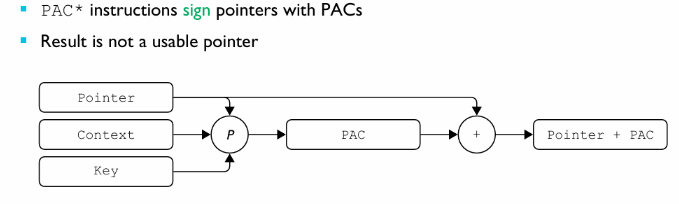
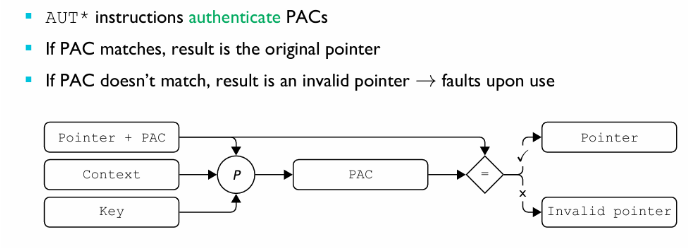
PAC 指令主要由两个步骤组成,签名 (sign) 和 校验 (authenticate):
文档
基于 Arm Architecture Reference Manual for A-profile architecture D8.10 Pointer Authentication 翻译并理解而来。
AArch64 支持对包含地址的 64 位通用寄存器内容进行指针验证码签名,并在该寄存器用作间接分支目标或加载/存储指令的基址寄存器之前,对带有 PAC 的寄存器内容进行认证。
** PAC 起效的一切前提是支持并实现了 FEAT_PAuth **
FEAT_PAuth
FEAT_PAuth 功能引入了对寄存器内容进行地址认证的支持,该操作在将寄存器用作间接分支的目标或作为加载操作的地址之前执行。当 PAuth 被实现后,以下所有的陈述都是正确的:
- 一定有一种 PAC 算法被实现了
PACGA指令和其他 PAC 指令使用了相同的算法
FEAT_PAuth 可选的算法有:
FEAT_PACIMPFEAT_PACQARMA5FEAT_PACQARMA3

该图是 ID_AA64ISAR1_EL1 寄存器字段示意图。
FEAT_PACIMP
FEAT_PACIMP 允许厂商使用自己的 PAC 加密算法实现,当 PACIMP 被实现时:
FEAT_PAuth一定被实现FEAT_PACQARMA5和FEAT_PACQARM3一定不被实现。
通过查看这两个字段 (ID_AA64ISAR1_EL1.GPI 和 ID_AA64ISAR1_EL1.API) 来判断 PACIMP 是否实现:

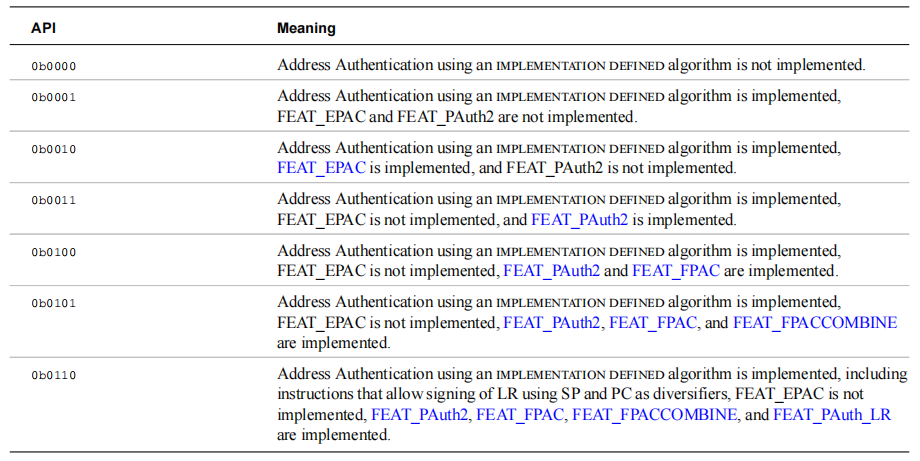
其中 FEAT_PAuth 被 ID_AA64ISAR1_EL1.API = 0b0001 所标记。
FEAT_PACQARMA5
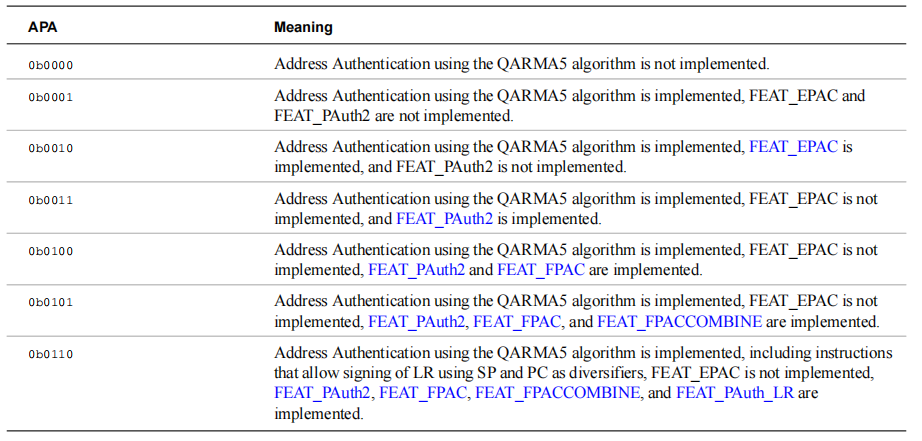
FEAT_PACQARM5 使用 QARM5 加密算法作为 PAC 的实现,通过查看这两个字段 (ID_AA64ISAR1_EL1.GPA 和 ID_AA64ISAR1_EL1.APA) 来判断 QARM5 是否被启用:

其中 FEAT_PACQARM5 被 ID_AA64ISAR1_EL1.APA 所标记。
FEAT_PACQARMA3
FEAT_PACQARM3 使用 QARM3 加密算法作为 PAC 的实现,通过查看这两个字段 (ID_AA64ISAR2_EL1.GPA3 和 ID_AA64ISAR2_EL1.APA3) 来判断 QARM5 是否被启用:

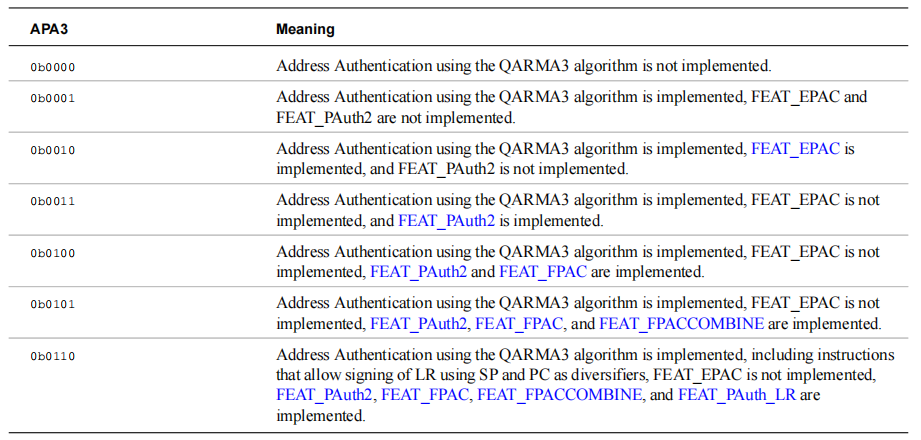
其中 FEAT_PACQARM3 被 ID_AA64ISAR2_EL1.APA3 所标记。

该图是 ID_AA64ISAR2_EL1 寄存器字段示意图。
PAC Usage
上文我们简单介绍了 PAC 的机制,现在我们来理解 PAC 是如何使用的,一个 PAC 指令主要可以分为三个部分:
PAC <TYPE> <XN|SP>
<TYPE>: 主要指的是加密类型,比如IA、IB,也就是说,对指令进行A/B加密<XN|SP>:主要指的是使用什么上下文进行加密
例如:
PACIASP
上面的指令的含义就是,使用密钥 A 和 SP 的上下文对 LR 寄存器进行 PAC 加密。类似的还有指令:
PACIX1716,这里的1716指的是寄存器X17, X16PACIXZ,这里的Z指的是zero
参考链接
Memory Tagging Extension
在上一节中,我们介绍了 PAC(Pointer Authentication Code) 的原理和简单使用,在 ArmV8 版本中,还提供一个全新的扩展名为 MTE(Memory Tagging Extension)。该特性同样利用了 TBI(Top-Byte Ignore) 的特性,使用指针的高 4 位存储 tag,在每个进程中有一段专用的内存用于存储 tag。当为内存制定了某个 tag 后,程序必须带上正确 tag 访问内存,若 tag 错误,程序抛出 SIGSEGV,如下图所示:
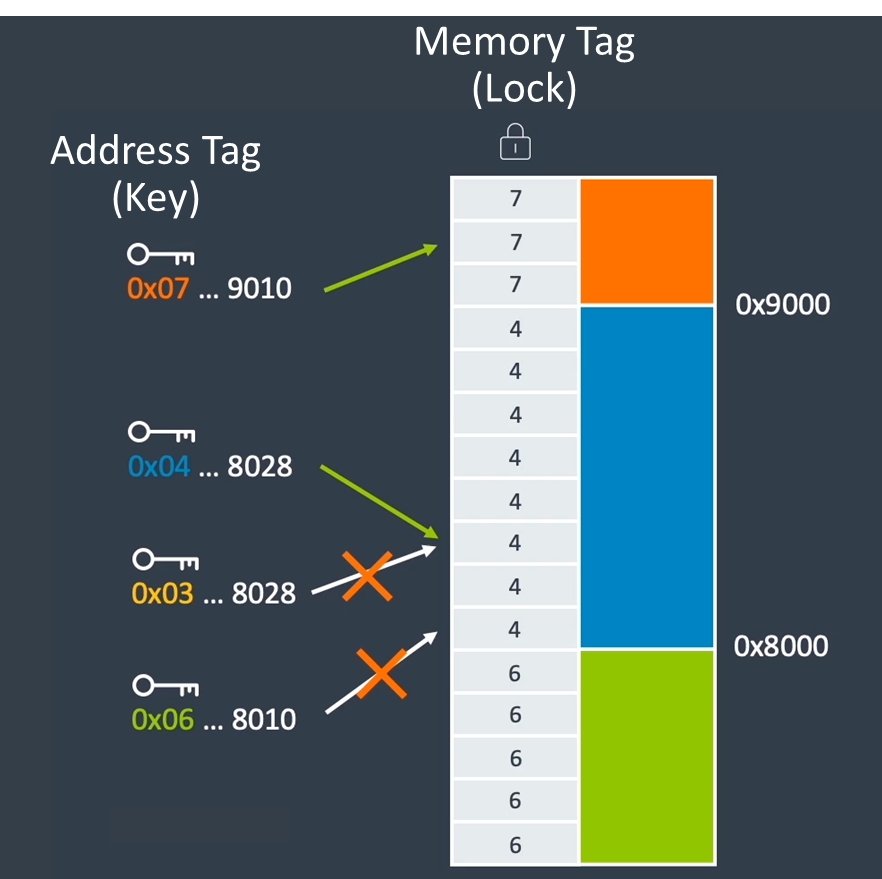
MTE 的原理是极其简单的,但如何正确的使用/实现 MTE 代码是一件比较复杂的事情 (至少比原理复杂很多)。ArmV8.5-A 提供了一套 MTE 扩展指令集来操作对应的 tag。因此,本节的核心是讲解 MTE 扩展指令集是如何使用,且会给出对应的例子。
MTE Core Instruction
MTE 提供了许多指令用于 tag 的操作,其核心的指令集是生成和使用对应的 tag,因此我个人认为 MTE 的扩展指令集核心指令就两条:
| Instruction | Example | Meaning |
|---|---|---|
| irg(Insert Random Tag) | IRG RD, RS, RM | 该指令会生成一个随机逻辑地址标签,并将其插入到第一源寄存器中的地址,最后将结果写入目标寄存器。在随机选择逻辑地址标签时,会排除可选的第二源寄存器或 GCR_EL1.Exclude 寄存器中指定的标签。 |
| stg(Store Allocation Tag) | STG RT, RS, #Imm | 该指令将一个分配标签存储到内存中。用于存储操作的地址根据基址寄存器和一个经过标签粒度缩放的有符号立即数偏移量计算得出。分配标签则来源于源寄存器中的逻辑地址标签。此指令会执行非检查访问。它包含三种编码类型:Post-index, Pre-index 和 Signed offset。 |
IRG Instruction
IRG 指令的第一个寄存器是 RD 寄存器,第二个寄存器是 RS 寄存器,第三个寄存器则是 RM 寄存器;当指令执行时,会生成一个随机 tag 值,并将该值直接插入到 RS 寄存器的高四位中,并写入到 RD 寄存器中;RM 寄存器若缺省则默认为 XZR。
irg x1, x0
IRG 指令会从 x0 寄存器中取值,并生成随机 tag 值,将该生成的 tag 值插入到 x0 寄存器中的值对应的标签位,并将整个指针 (带标签) 写入到 x1 寄存器中。但是,需要注意,IRG 并不会修改 x0 本身的值,只是将 x0 的值取出后进行组装。

STG
STG 指令的第一个寄存器是 RS 寄存器 (源寄存器),第二个寄存器是 RN 寄存器 (基址寄存器),第三个字段是立即数值;当指令执行时,STG 会将源寄存器中的 tag 存放到由基址寄存器和立即数值 (offset) 计算得出的位置。立即数值若缺省则默认为 0。
由于 STG 指令需要寻址,因此就需要引入 Arm 中的三种寻址模式:
- Post-index
Post-index 也就是先使用,后更新,其表示形式如下:
# STG RT, [RS], #Imm9
stg x1, x0, #16
假设 x1 是通过 irg 生成的随机 tag,在这种模式下,STG 会先从 x0 寄存器中取出基址进行填入 tag 在基址对应的标签地址处,然后再将 x0 与立即数相加得到新的基址。

- Pre-index
Pre-index 也就是先更新,后使用,其表示形式如下:
# STG RT, [RS, #Imm9]!
stg x1, [x0, #16]!
假设 x1 是通过 irg 生成的随机 tag,在这种模式下,STG 会先将 x0 寄存器和立即数进行相加,而后将 tag 填入到相加后的基址对应的标签地址处。

- Signed offset
Signed offset 也就是只使用,不更新,其表示形式如下:
# STG RT, [RS, #Imm9]
stg x1, [x0, #16]
假设 x1 是通过 irg 生成的随机 tag,在这种模式下,STG 会先将 x0 寄存器和立即数进行相加得到临时值,而后将 tag 填入到相加后的基址对应的标签地址处。注意,这一种类型需要和 Pre-index 区分,Signed offset 不会更改基址寄存器的值。

MTE Other Instruction
上面我们介绍完核心的两个指令后,我们可以通过一个简单的表格来看看其余 MTE 扩展指令:
| Instruction | Name | Format |
|---|---|---|
| ADDG | Add withe Tag | ADDG RD, RS, #Imm6, #Imm4 |
| CMPP | Compare with tag | CMPP RN, RM |
| GMI | Tag Mask Insert | GMI RD, RS, RM |
| ST2G | Store Allocation Tags to two granules | ST2G RT, [RS], #Imm9 ST2G RT, [RS, #Imm9]! ST2G RT, [RS, #Imm9] |
| STGP | Store Allocation Tag and Pair | STGP RT1, RT2, [RS], #Imm9 STGP RT1, RT2, [RS, #Imm9]! STGP RT1, RT2, [RS, #Imm9] |
| STZ2G | Store Allocation Tags to two granules Zeroing | STZ2G RT, [RS], #Imm9 STZ2G RT, [RS, #Imm9]! STZ2G RT, [RS, #Imm9] |
| STZG | Store Allocarion Tag Zeroing | STZG RT, [RS], #Imm9 STZG RT, [RS, #Imm9]! STZG RT, [RS, #Imm9] |
| SUBG | Subtract with Tag | SUBG RD, RS, #Imm6, #Imm4 |
| SUBP | Subtract Pointer | SUBP RD, RN, RM |
当然,上述只是一部分 MTE 扩展指令,更多的请自行参阅 ArmV8.5-A 手册。
Example
在上文我们了解了 MTE 扩展指令集是什么,以及 MTE 的原理。现在我们来尝试通过一个例子来学习 MTE 扩展如何实际使用 (点击此处查阅完整代码)。
/*
* Insert a random logical tag into the given pointer.
*/
#define insert_random_tag(ptr) ({ \
uint64_t __val; \
asm("irg %0, %1" : "=r" (__val) : "r" (ptr)); \
__val; \
})
/*
* Set the allocation tag on the destination address.
*/
#define set_tag(tagged_addr) do { \
asm volatile("stg %0, [%0]" : : "r" (tagged_addr) : "memory"); \
} while (0)
MTE 扩展并没有对应的 builtin function(内建函数) 实现,因此,如果我们想要使用 MTE 扩展,就需要通过内联汇编进行操作,如上就是 C 语言中对于 irg 和 stg 指令的封装宏。
#define HWCAP2_MTE (1 << 18)
unsigned long hwcap2 = getauxval(AT_HWCAP2);
if (!(hwcap2 & HWCAP2_MTE))
return EXIT_FAILURE;
我们想要使用 MTE 扩展,就必须先判断当前 CPU 架构是否支持 MTE 扩展,而在内核向用户空间中提供 MTE 扩展是通过的 HWCAP2_MTE 宏。当确认 CPU 架构支持开启 MTE 扩展后,我们还需要判断 TBI 是否被启用:
if (prctl(PR_SET_TAGGED_ADDR_CTRL,
PR_TAGGED_ADDR_ENABLE | PR_MTE_TCF_SYNC | PR_MTE_TCF_ASYNC |
(0xfffe << PR_MTE_TAG_SHIFT),
0, 0, 0)) {
perror("prctl() failed");
return EXIT_FAILURE;
}
这里启用了标签地址 ABI 允许用户空间进程使用地址的最高字节来存储内存标签,也就意味着 MTE 功能被开启。PR_MTE_TCF_SYNC 和 PR_MTE_TCF_ASYNC 用于设置标签检查故障 (Tag Check Fault, TCF) 的检测模式
PR_MTE_TCF_SYNC:如果发生内存标签不匹配(即指针标签和内存标签不一致),会立即导致一个同步的 SIGSEGV 信号被发送给进程,其行为类似硬件错误(如除以零)。这种模式能提供精确的故障点定位。PR_MTE_TCF_ASYNC:如果发生标签不匹配,处理器不会立即停止,而是在不影响性能的情况下,将故障信息异步地记录下来。它会在稍后的时间点(例如在进入内核或通过其他机制检查时)触发信号。这种模式的性能开销较小,但定位故障点不够精确。
当同时指定这两个 flag 时,通常表示程序允许在这两者之间选择一个模式允许,由 CPU 以及具体实现来自动选择。而 0xfffe 表示允许 MTE 在分配内存时使用标签 1 到标签 15 进行随机分配,禁用了标签 0。最后三位参数均设为 0 是固定搭配。
unsigned char *a;
unsigned long page_sz = sysconf(_SC_PAGESIZE);
a = mmap(0, page_sz, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (a == MAP_FAILED) {
perror("mmap() failed");
return EXIT_FAILURE;
}
/*
* Enable MTE on the above anonymous mmap. The flag could be passed
* directly to mmap() and skip this step.
*/
if (mprotect(a, page_sz, PROT_READ | PROT_WRITE | PROT_MTE)) {
perror("mprotect() failed");
return EXIT_FAILURE;
}
/* access with the default tag (0) */
a[0] = 1;
a[1] = 2;
在这一步,我们就需要验证该程序是否在进程内成功启用了 MTE,首先获取系统的页大小,为后续从 mmap 中申请空间做出准备。通过 mprotect 来修改已分配内存的保护标志,启用真正的 MTE 功能。通常而言,mmap 和 mprotect 操作返回的原始指针,在没有经过显示 IRG 操作的情况下,默认的指针标签是 0。
因此,我们通过 a[0] = 1 这样的代码进行访问,确定了目前是合法的。
/* set the logical and allocation tags */
a = (unsigned char *)insert_random_tag(a);
set_tag(a);
/* non-zero tag access */
a[0] = 3;
/*
* If MTE is enabled correctly the next instruction will generate an
* exception.
*/
a[16] = 0xdd;
然后,我们通过 insert_random_tag 为 a 地址生成一个随机标签,并通过 set_tag 将生成的地址标签应用到这块地址中。
irg x20, x20
stg x20, [x20]
ldrb w2, [x20, #1]
mov w8, #3
mov x0, x19
mov w1, #3
strb w8, [x20]
bl printf
然后访问 a[0],可以发现此时是正常访问的,因为当前程序带有了正确的标签,该标签管理了一块 16 字节大小的内存空间。a[16] 的访问我们认为会导致一个 MTE 异常,因为 a[16] 不在当前标签的管理范围内,因此生成的标签与 a[16] 的地址标签不相同 (\( Tag_{irg} \ne Tag_{0} \))。
参考链接
- Where is the MTE Tag stored and checed?
- Linux Mem – MTE in AArch64 Linux
- Memory Tagging Extension (MTE) in AArch64 Linux
RISC-V
CHERI(Capability Hardware Enhanced RISC Instructions,能力硬件增强型 RISC 指令集)扩展旨在为 RISC-V 架构引入细粒度的内存保护和可扩展的软件划分(或称隔离)功能,以解决 C/C++ 等传统语言中长期存在的内存安全漏洞问题。
- CHERI Introduce:介绍 CHERI 扩展的主要工作原理
CHERI Introduce
CHERI (Capability Hardware Enhanced RISC Instructions) 通过新的架构特性扩展了传统的硬件指令集架构 (ISAs),从而实现细粒度 (fine-grained) 的内存保护和高度可扩展 (highly scalable) 的软件划分。
CHERI 是一个硬件/软件/语义 (hardware/software/semantics) 协同设计项目,结合了架构设计、硬件实现、主流软件栈的适配以及形式化语义和证明。
本章主要讲解 CHERI 的原理以及其表现形式。
The CHERI Architecture
CHERI 扩展了使用机器码 (machine words) 来表示语言层面的整数和指针的传统指令集;采用了一种新的硬件支持的类型数据,名为 Architectural Capability (架构能力,后续称为 capability)。Capability 可用于保护那些旨在用作代码或数据指针的 (Virtual) 地址——包括源语言产生的地址,以及那些用于语言特性底层实现的地址。
与现有类型的硬件支持的数据 (整数、浮点数、向量等等) 一样,Capability 使用新的指令 (Capability-aware Instructions) 来加载、存储和操作。
Capabilities
在 CHERI 的设计中,Capability 是基线架构中原生整数指针类型宽度的两倍,例如:64 位平台上为 128 位 Capability。因为 Capability 类似于一种携带元数据的 “Fat Pointer”,为了容纳这些元数据,CHERI 架构选择将总宽度增加一倍以高效的存储地址和安全元数据。
这里的 “Fat Pointer” 是我个人的理解,Capability 在中文中的含义是能力,也就是说 Architectural Capability 是通过携带了额外元数据来使得该 Pointer 具有一定的功能来完成所需要的操作行为 (Capability)。
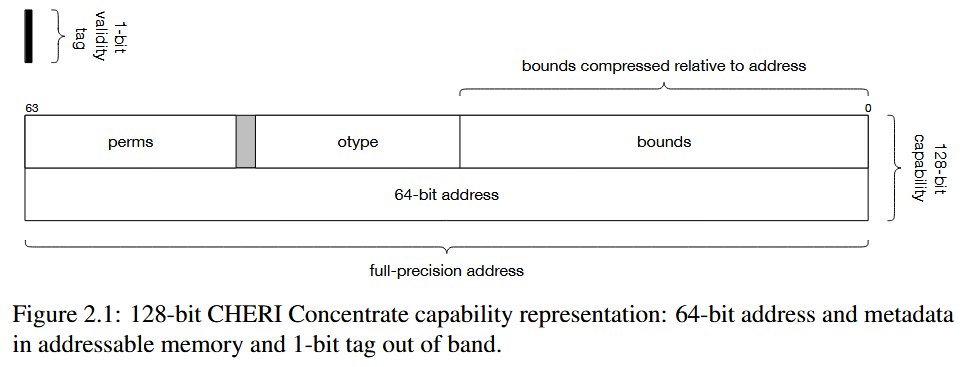
Capability 的字段由上图可见,其中每一个元素都有助于保护 CHERI 模型,并且由硬件强制执行:
- Validity Tag:有效性标签跟踪一个 Capability 的有效性;如果该 Capability 无效,则不能用于任何加载、存储、指令获取或其他操作。如果遵循 Architectural Rules for Capability Use 所描述的规则,仍可以从一个无效的 Capability 中提取出对应的字段,包括其地址;而 Capability-aware 指令在 Capability 被加载、存储以及在 Capability 字段被访问、操作和使用时都会保持该有效性标签 (如有需要)。
- Bounds:上界和下界描述了 Capability 授权进行加载、存储和指令获取的地址空间的权限范围。
- Permissions:权限掩码 (Permissions mask) 控制了 Capability 的使用方式,例如,通过限制数据的加载、存储或限制 Capability 本身的加载和存储等等。
- Object Type:对象类型 (Object Type) 字段如果不等于
-1,则对应的 Capability 被这个对象类型所密封 (“Sealed”),并且不能被修改和解引用。

Address Field
Capability 的低 XLEN 位编码指向了 Capability 指向的地址。这也被称为 Capability 的整数部分。对于被扩展但当前持有无效的 Capability 数据的寄存器,所有其他字段通常为零。
Capability Tag Field (Validity Tag)
Capability 标签**是一个额外的附加位,被添加到可寻址内存和所有 YLEN 位的寄存器中。它可以被单独存储,并且可能被称为 “out of bound” 或隐藏的,并由硬件管理。**该标签指示一个 YLEN 位的寄存器或 YLEN 位对齐的内存位置是否包含一个有效的 Capability。如果该标签被设置,则对应的 Capability 是有效的,并且可以被解引用 (具体允许的操作取决于权限)。
所有能够容纳一个 Capability 的寄存器或内存位置都是具有 YLEN 位的宽度,并且附加了一个 Capability 有效位标签。
值得注意的是,Capability 标签不能够被常规意义上通过位操作置一来启用。如果 Capability 标签被启用,则表明该 Capability 是根据 Architectural Rules for Capability Use 所表述的规则正确派生 (derived) 出来的。如果遵循这些规则,那么在修改、加载或者存储 Capability 的指令执行过程中,该标签得以传播。
因此,对于寄存器中的 Capability 操作有以下规则:
- Provenance Check:任何将 Capability 写入寄存器的指令,其输入操作数中至少有一个 Capability 标签被设置。
- 这遵循了有效性原则,一个新的 Capability 的建立一定是由一个已经存在的 Capability 通过指令创建的。
- Montonicity Check:任何将 Capability 写入寄存器的指令,都需要保证该操作不会增加 Bound 或者权限,并且设置了输出上的 Capability 的有效性标签。
- 这遵循了单调性原则,一个衍生 Capability 的权限不会超过其父类的权限集合。
- Integrity Check:任何将 Capability 写入寄存器的指令,都会检测是否存在被损坏的值。
- 这确保了 Capability 的各项元数据是合法并且正确的。
- Capability 的加载和存储操作都需要经过 Provenance Check:
- 任何将 Capability 写入内存的存储操作都经过了正确的授权
- 任何从内存中读取 Capability 的加载操作都经过了正确的授权
- 当一个操作由于软件错误或恶意企图而未能通过检查时,该操作会引发一个异常(exception)或将所产生的 Capability 对应的标签设置为零。
- 使用无效的 Capability 来解引用内存或授权任何操作都会引发异常。所有源自无效的 Capability 的衍生 Capability 都是无效的,即它们的 Capability 标签为零。
Capability tags in registers
每个 YLEN 位的寄存器都带有一个一位的 Capability 标签,用于指示寄存器中的 Capability 是否有效,可以被解引用。每当执行无效的 Capability 操作时,该标签就会被清除。此类无效操作的例子包括:只写入寄存器的整数部分(地址字段),或试图增加边界或权限。
Capability tags in memory
Capability 标签是通过内存子系统进行跟踪的:每个对齐的 YLEN 位宽区域都有一个不可寻址的一位 Capability 标签,硬件会与数据一起以原子方式管理它。
如果该 YLEN/8 对齐内存区域中的任何字节被写入时,所使用的操作不是一个合法的 Capability 存储操作或该操作不具备设置标签的权限又或是被存储的 Capability 本身的标签就是无效的,那么该 Capability 标签就会被清除为零。
所有存储 Capability 的系统内存和缓存都必须保留这种抽象,以原子方式处理 Capability 标签和数据。
Capability Bounds Field
Capability 编码了内存边界 (Bounds),即当被解引用以进行数据内存访问或指令执行时,允许其访问的内存中的最低和最高字节。
检查是按字节进行的,因此内存访问可能是完全在边界内 (fully in-bounds)、部分超出边界 (partially out-of-bounds) 或完全超出边界 (fully out-of-bounds)。不允许进行任何部分或完全超出边界的内存访问。
每个 Capability 都有两个内存地址边界:
- 基址 (Base):代表最低可访问字节,Base 是
XLEN位宽的,并且是包含的 (inclusive) - 顶址 (Top):代表最高可访问字节之上的一个字节,Top 是
XLEN + 1位宽的,并且是排他的 (exclusive)
因此,一个 Bounds 所表达的范围为:\( Top - Base, [Base, Top)\)。因此对于一个内存地址 A 而言,如果 \( Base \le A \lt Top \) A 位于边界内,则说明其是可以有效被访问的。
检查每条已执行指令的每个字节和每次数据内存访问的每个字节,是 CHERI 提供的内存安全性的基础。在一个典型的加载/存储单元中,对来自
rs1的边界扩展和边界检查是与地址计算、内存转换和 (或) PMA/PMP 检查并行进行的。
Capability 中边界的编码采用了类似浮点数的方案 (该压缩方法较为复杂,因此目前暂且不分析),使用一个指数 (exponent) 和一个尾数 (mantissa) 的压缩格式。因此,较小的指数可以允许边界具有字节级 (byte granularity) 的粒度,而较大的指数则会给出更粗糙的粒度 (coarser granularity)。
在 CHERI 中,提供了两条指令进行获取边界的元数据:YBASE 和 YLENR,通过这两个指令的结果进行加法运算即可得到可访问的最高位地址。需要注意的是,YBASE 和 YLENR 寄存器的结果采用的是饱和加法计算 (Saturating Addition,当运算结果溢出时,其结果会直接固定在最大的可能值上,即\( A + B \ge 2^N - 1, A + B = 2^N - 1\))。


Cpability Type Field (CT, Object Type)
这个元数据值指示了 Cpability 的类型。在 RVY 基础指令集架构中定义的唯一类型是 0。
类型决定了该 Cpability 授权哪些操作;RVY 的扩展将定义额外的类型,并为具有此类类型的 Cpability 赋予额外的语义。一个给定的 CHERI 平台支持哪些 Cpability 类型,取决于所使用的扩展和 Capability 编码格式。
Cpability 编码格式还会指定一种映射,将格式中的某些位 (通常描述为“CT 字段”) 与 Cpability 类型的空间关联起来。该映射必须能够编码 Type 0,但几乎没有其他要求。例如,它不需要被解释为 CT 值的(带符号或无符号)二进制表示。
- Unsealed Capability
- 当 \( CT = 0 \) 时,该 Cpability 授权访问一块内存区域,其具体权限和界限由 Cpability 中的权限 (permissions) 和 界限 (bounds) 字段定义。
- Sealed Cpability
- 当 \( CT \ne 0 \) 时,该 Capability 被密封 (Sealed);不能被修改,也不能被解引用来访问内存。如果对 Capability 进行操作的指令遇到了密封的 Capability,并且该操作会改变其地址、界限或权限,则会产生一个 Capability 标签被清除的结果 (即结果不再是一个有效的 CHERI Capability)。任何扩展如果增加了 Capability 的元数据,必须描述他们与被密封的 Capability 之间的交互方式。
给定一个 \( CT = 0 \) 的 Capability,从中派生出一个 \( CT \ne 0 \) 的 Capability,这个过程被称为密封 (Sealed)。如果特指输出的 Capability 类型,则称为以类型 x 密封 (sealing with type x),其中 \( CT = 0 \) 是指特定的非零 Capability 类型。
反之,从一个 \( CT \ne 0 \) 的 Capability 中派生出一个 \( CT = 0 \) 的 Capability,这个过程被称为解封 (unsealing)。如果特指输入的非零 Capability 类型,则称为从类型 x 解封 (unsealing from type x),其中 \( CT = 0 \) 是指特定的非零 Capability 类型。
- Ambient Sealing Type (环境密封类型)
- 某些 Capability 类型被称为环境可用 (ambiently available)(或简称“环境类型”),如果它们不需要特定的授权即可用作密封一个 Capability (用该类型) 的类型。
- 例如,如果 Zys 在给定平台上可用,那么它用来密封 Capability 的那个类型就被认为是环境可用的。(在使用 Zydefaultcap 的 Capability 编码时,该类型将是类型 1。)
- Sentry Capability Type (哨兵 Capability 类型)
- 在 CHERI 软件系统中,拥有不可变 (immutable) 的函数指针是非常有用的。密封的 Capability (Sealed capabilities) 是一个自然的基础,因为它们提供了不可变性。JALR (RVY) 指令在将 Capability 安装到程序计数器 (program counter) 之前,可能会解封 (unseal) 具有特定、由编码格式指定的类型的 Capability。使用此类类型密封的 Capability 被称为**“哨兵” (sentries)**(这个词是 “sealed entries” 即“密封入口”的合成词)。JALR (RVY) 也可能使用由编码格式指定的类型,来密封它生成的返回指针 (return pointers)。
Architecture Permissions Field (AP, Permissions)
这个元数据字段编码了 Capability 架构上定义的权限,权限授予访问权限的前提是:
- Capability 标签必须设置被有效状态
- 该 Capability 必须未密封 (Unsealed)
- 界限检查必须通过
值得注意的是,任何操作还取决于其他 RISC-V 架构特性(例如虚拟内存、PMP 和 PMA)所施加的要求,即使 Capability 本身授予了足够的权限。目前在 RVY 中定义的权限列在下方。权限可以在派生新的 Capability 值时(使用 YPERMC 指令)被清除 (cleared),但它们永远不能被添加。
| Permission | Type | Comment |
|---|---|---|
| R | Data memory permission | Authorize data memory read access,Allow reading data from memory |
| W | Data memory permission | Authorize data memory write access,Allow writing data to memory |
| X | Instruction memory permission | Authorize instruction memory execute access,Allow instruction execution |
| C (Capability) | Data memory permission | Authorize loading/storing of capability tags |
| LM (Load Muatble) | Data memory permission | Used to restrict the permissions of loaded capabilities |
| ASR (Access System Registers) | Privileged state permission | Authorize privileged instructions and CSR accesses |
C (Capability) 权限控制着内存加载和存储操作中 Capability 标签 (capability tags) 的处理方式:如果同时授予了 R/W 权限,那么就允许从内存中读取 Capability 标签/将 Capability 标签写入到内存;但如果 C 权限缺失,那么在执行 Capability 加载 (capability loads) 和 Capability 存储 (capability stores) 操作时,Capability 标签将被读取和写入为零 (zero)。
| Who | Permission | Operation | Result | Rules |
|---|---|---|---|---|
| \( C_{ptr} \) | R, W, C | \( C_{ptr} \) 将内存 A 处的 Capability 加载到寄存器中 | 寄存器获得带有完整标签的 Capability C | C 权限允许读取标签 |
| \( C_{data} \) | R, W | \( C_{data} \) 将内存 A 处的有效 Capability 加载到寄存器中 | 寄存器获得标签被清除的 Capability,转变为一个普通指针 | C 权限缺失,标签被读取清零 |
| \( C_{store} \) | R, W | \( C_{store} \) 将一个有效 Capability 存储到内存地址 A 处 | 内存 A 处存储的值标签被清除,只存储数据部分 | - |
LM (Load Muatble) 权限授权保留从内存中加载的 Capability 的 W 权限 (Write Permission)。如果一个 Capability 授予了 R 权限和 C 权限,但没有授予 LM 权限,那么通过这个授权 Capability 加载的 Capability 将失去其 W 权限和 LM 权限 (当然,必须满足 CHERI 被启用且非密封权限)。
假设有一个代码段要将一块可写内存的 Capability \( C_{src} \) 传递给另一个代码段,且 C_{src} 拥有 R, W, C, LM 权限。
| Who | Permission | Operation | Result | Rules |
|---|---|---|---|---|
| \( C_{auth} \) | R, C, LM | \( C_{auth} \) 从内存中加载 \( C_{src} \) | \( C_{dst} \) 拥有 R, W, C, LM 权限 | \( C_{auth} \) 授予了 LM 权限,因此允许保留 \( C_{src} \) 中的 W 权限 |
| \( C_{auth} \) | R, C | \( C_{auth} \) 从内存中加载 \( C_{src} \) | \( C_{dst} \) 拥有 R, C 权限,缺失 M,LM 权限 | \( C_{auth} \) 未被授予 LM 权限,因此不被允许保留 \( C_{src} \) 中的 W 权限 |
ASR (Access System Registers) 主要用于授权对控制和状态寄存器 (CSR) 的访问:授权对所有特权 CSR、一些非特权 CSR 以及一些特权指令进行读写访问。在 RVY 中,唯一受影响的 CSR 是非特权的 utidc CSR。写入 utidc CSR 需要 ASR 权限,但读取则不需要。
ASR 权限的权限检查总是使用程序计数器 (PC) 中的权限。
Architectural Rules for Capability Use
CHERI 架构在修改 Capability 元数据时强制执行几项重要的安全属性。首先涉及单条指令执行的属性:
- Provenance Validity (来源有效性):确保有效 Capability 只能通过显式构造的指令(例如,不能通过字节操作)从其他有效的 Capability 中创建。此属性适用于寄存器和内存中的 Capability (capability in register, capability in memory)。
- Capability Monotonicity(单调性):确保任何指令构造新的 Capability 时(密封操作和异常引发除外),其权限和范围不得超过派生该 Capability 的原始 Capability。
- Reachable Capability Monotonicity (可达单调性):确保任意代码执行过程中,在将执行权移交给其他域之前,可达 Capability 的集合(当前程序状态可通过寄存器、内存、密封、解封及构造子 Capability 访问的 Capability)不会增加。
在启动时 (boot time),架构为固件提供初始的 Capability,允许跨整个地址空间进行数据访问和指令获取。同时,所有内存中的标签被清除。随后,当 Capability 从固件传递到引导加载程序、从引导加载程序到虚拟机监视器、从虚拟机监视器到操作系统,再从操作系统到应用程序时,可按照单调性属性派生出新的 Capability。在派生链的每个阶段,权限和范围可被进一步限制以缩小访问范围。
同样,Capability 具有intentionality (意图传递性):当进程将能力作为参数传递给系统调用时,操作系统内核可谨慎地仅使用该能力进行操作,确保不会访问用户进程未授权的其他进程内存——即使内核可能通过其持有的其他能力拥有访问整个地址空间的权限。这一点非常重要,因为它防止了“权限混淆“问题,即高权限方代表低权限方行动时,滥用超额权限执行非授权操作。
General-Purpose Capability Registers
CHERI Capability 可以保存在 Capability 寄存器中——即经过扩展以容纳 Capability 标签和完整的数据宽度的架构寄存器——也可以保存在带标签的内存中。当 Capability 位于寄存器中时,它们可以作为 Capability-Aware 指令的操作数,用于检查、操作、解引用或以其他方式对 Capability 进行操作。
对于通用寄存器文件,CHERI 可以通过两种方式实现:
- 分离式寄存器文件 (A Split Capability Register File):引入一个新的通用 Capability 寄存器文件,类似于浮点寄存器文件,以补充现有的通用整数寄存器文件。
- 融合式寄存器文件 (A Merged Capability Register File):扩展现有的通用整数寄存器,使其包含容纳 Capability 所需的标签和额外宽度,类似于将 16 位架构扩展到 32 位、或将 32 位架构扩展到 64 位的做法。
随着 Capability 在寄存器和内存之间移动,标签会跟踪有效、未损坏的 Capability 在整个系统中的流向,从而控制 Capability 未来的使用。
对于 Capability 寄存器本身,而不仅仅是内存位置,进行标签标记可以实现对 Capability 无感知 (capability-oblivious) 的代码(capability-oblivious code):例如,C 语言的 memcpy() 函数会利用 Capability 加载和存储指令,以便在适当对齐的内存复制操作中,任何有效的标签都将被保留,从而保持指针的可解引用性,但同时它也能够复制未带标签的普通数据。

Special Capability Registers
除了通用 Capability 寄存器之外,一些现有的专用寄存器需要扩展到 YLEN 宽度,并且还需要一些全新的 Capability 宽度专用寄存器。
例如,架构的程序计数器 (Program Counter, PC) 和异常程序计数器 (Exception Program Counter, EPC) 被扩展为完整的 Capability,从而允许 Capability 约束控制流 (PCC),并在异常处理期间得到正确的保存和恢复 (EPCC)。
另一个专用的 Capability 寄存器是 DDC (Default Data Capability),它自动地间接控制所有基于整数的加载和存储操作,从而允许使用 Capability 来约束非能力感知代码。
根据基线架构的不同,可能还需要其他扩展,例如处理基于 Capability 的线程本地存储 (Thread-Local Storage) 访问。

Capability-Aware Instructions
CHERI 新增了一些指令集到基线架构中,用来执行如下几类函数:
- Retrieve capability fileds (检索能力字段):检索各种 Capability 字段的整数值,包括其标签 (tag)、地址 (address)、权限 (permissions) 和对象类型 (object type)
- Manipulate capability fields (操纵能力字段):设置或修改各种 Capability 字段,受限于单调性原则(即只能缩小权限或范围,不能扩大),包括地址、权限和对象类型。
- Load or store via capabilities (通过 Capability 加载或存储):通过一个获得适当授权的 Capability 来加载或存储整数、Capability 或其他值。
- Control flow (控制流):执行跳转 (jump) 或跳转并链接寄存器 (jump-and-link-register, JALR) 到一个 Capability 目标地址。
- Special capability registers (特殊能力寄存器):检索和设置特殊能力寄存器的值——例如,在异常处理期间异常程序计数器能力 (Exception Program-Counter Capability, EPCC) 的值。
- Compartmentalization (区隔化):这些指令支持快速保护域 (protection-domain) 转换。
CHERI 的一个重要方面在于其 Intentionality (意图性原则):
- 指令期望的操作数要么是能力 (capability),要么是整数 (integer)。
- 指令绝不会根据标签值动态地选择一种解释或另一种解释。
- 安全机制:如果一个能力相对的加载、存储或其他操作试图使用一个无标签的能力值 (untagged capability value) 进行访问,将抛出硬件异常。
Papers
本栏目聚焦计算机安全方向的前沿学术论文研读与知识沉淀,内容涵盖我自主整理的论文 PDF 文档、深度阅读笔记及研读感悟。为尊重知识产权并保障资料使用的规范性,所有提供的 PDF 文件均添加了防扩散水印及访问加密保护(如需获取原文资料,请点击此处填写需求信息,我将及时与您联系)。
当前分类体系
- Security: 聚焦网络安全、系统安全、应用安全等核心领域的经典与突破性研究
已收录论文概览
- KNighter SOSP’25: 深度解析 SOSP 2025 会议中关于“LLM Static Analyzer“的创新性研究成果